 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020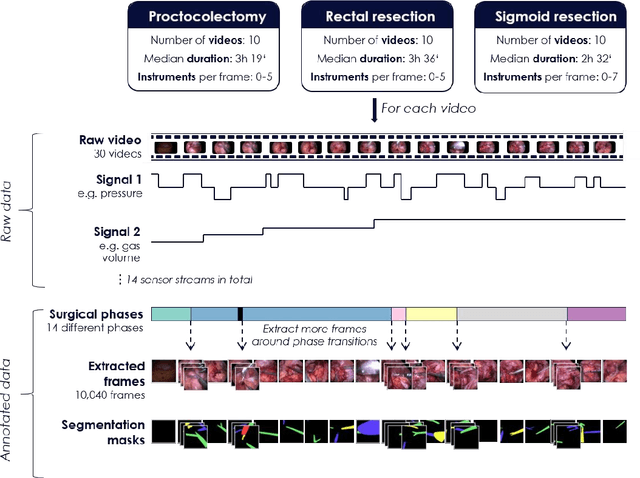
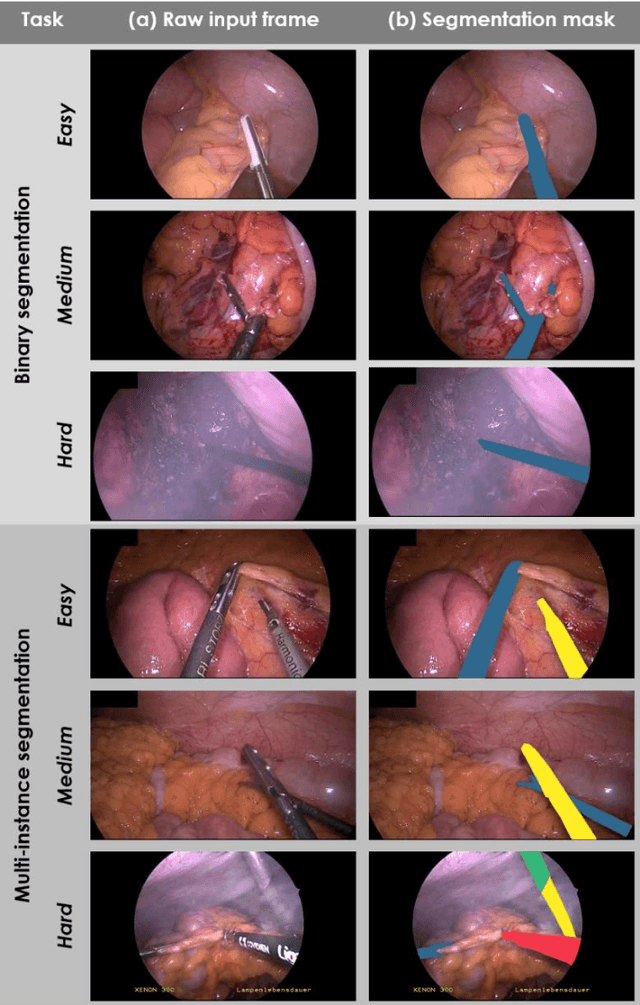
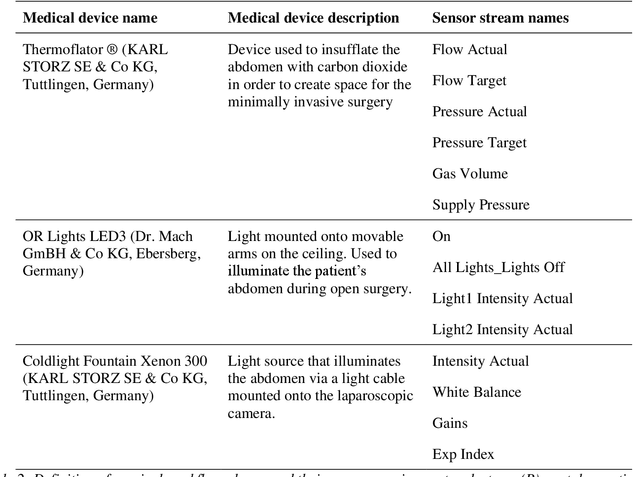
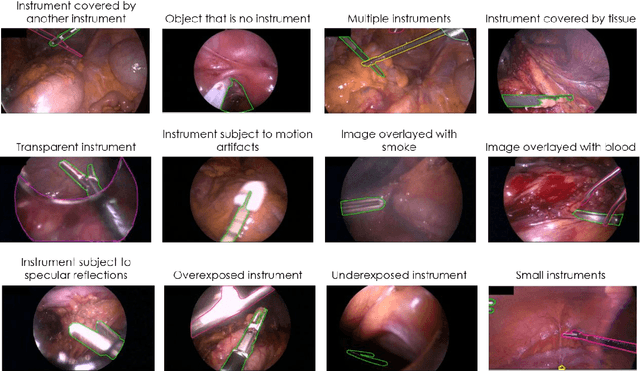
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Exploiting the potential of unlabeled endoscopic video data with self-supervised learning
Jan 31, 2018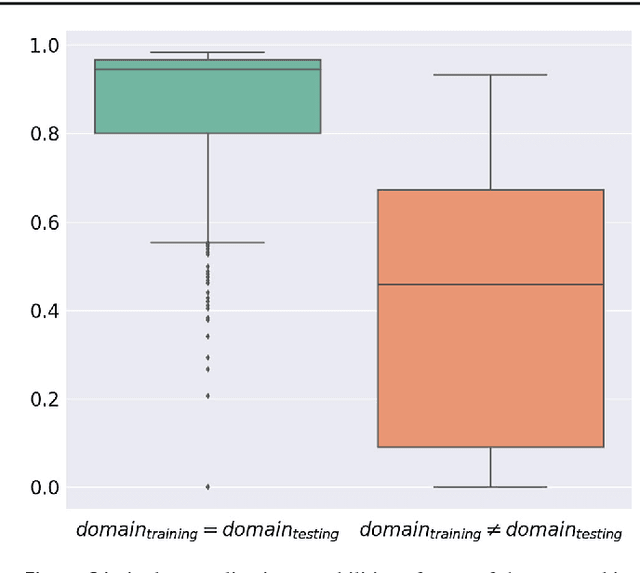
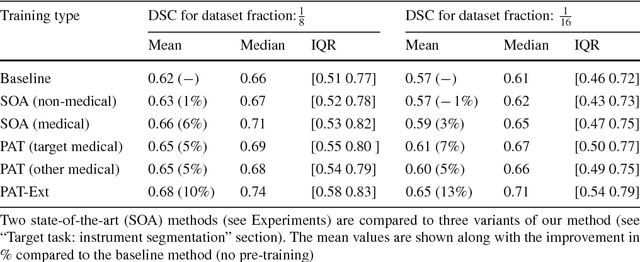
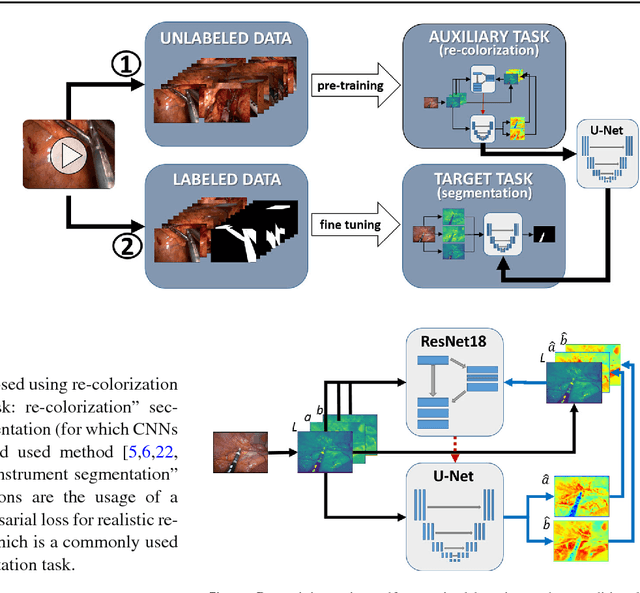
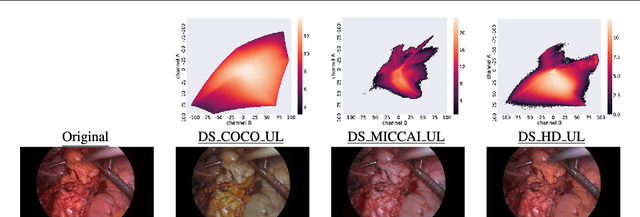
Surgical data science is a new research field that aims to observe all aspects of the patient treatment process in order to provide the right assistance at the right time. Due to the breakthrough successes of deep learning-based solutions for automatic image annotation, the availability of reference annotations for algorithm training is becoming a major bottleneck in the field. The purpose of this paper was to investigate the concept of self-supervised learning to address this issue. Our approach is guided by the hypothesis that unlabeled video data can be used to learn a representation of the target domain that boosts the performance of state-of-the-art machine learning algorithms when used for pre-training. Core of the method is an auxiliary task based on raw endoscopic video data of the target domain that is used to initialize the convolutional neural network (CNN) for the target task. In this paper, we propose the re-colorization of medical images with a generative adversarial network (GAN)-based architecture as auxiliary task. A variant of the method involves a second pre-training step based on labeled data for the target task from a related domain. We validate both variants using medical instrument segmentation as target task. The proposed approach can be used to radically reduce the manual annotation effort involved in training CNNs. Compared to the baseline approach of generating annotated data from scratch, our method decreases exploratively the number of labeled images by up to 75% without sacrificing performance. Our method also outperforms alternative methods for CNN pre-training, such as pre-training on publicly available non-medical or medical data using the target task (in this instance: segmentation). As it makes efficient use of available (non-)public and (un-)labeled data, the approach has the potential to become a valuable tool for CNN (pre-)training.
Knowledge Fusion via Embeddings from Text, Knowledge Graphs, and Images
Apr 20, 2017
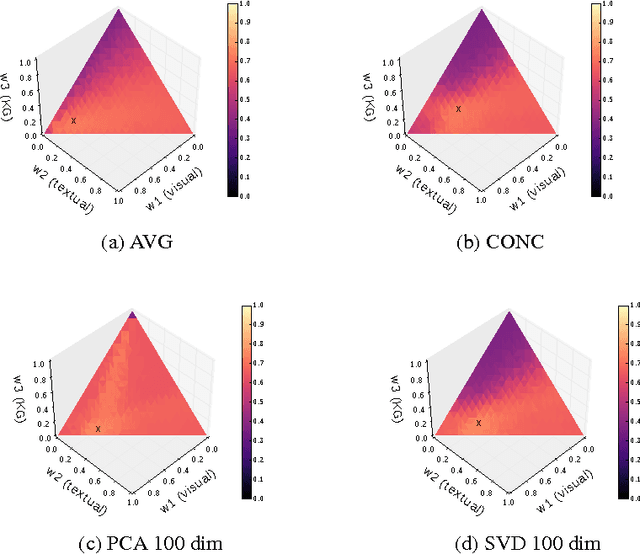
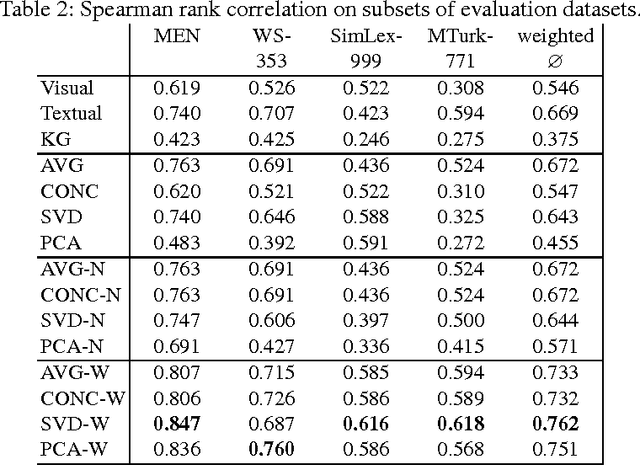
We present a baseline approach for cross-modal knowledge fusion. Different basic fusion methods are evaluated on existing embedding approaches to show the potential of joining knowledge about certain concepts across modalities in a fused concept representation.