 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Representation Guidance for Diffusion Models with a Representation Alignment Projector
Jan 30, 2026Recent progress in generative modeling has enabled high-quality visual synthesis with diffusion-based frameworks, supporting controllable sampling and large-scale training. Inference-time guidance methods such as classifier-free and representative guidance enhance semantic alignment by modifying sampling dynamics; however, they do not fully exploit unsupervised feature representations. Although such visual representations contain rich semantic structure, their integration during generation is constrained by the absence of ground-truth reference images at inference. This work reveals semantic drift in the early denoising stages of diffusion transformers, where stochasticity results in inconsistent alignment even under identical conditioning. To mitigate this issue, we introduce a guidance scheme using a representation alignment projector that injects representations predicted by a projector into intermediate sampling steps, providing an effective semantic anchor without modifying the model architecture. Experiments on SiTs and REPAs show notable improvements in class-conditional ImageNet synthesis, achieving substantially lower FID scores; for example, REPA-XL/2 improves from 5.9 to 3.3, and the proposed method outperforms representative guidance when applied to SiT models. The approach further yields complementary gains when combined with classifier-free guidance, demonstrating enhanced semantic coherence and visual fidelity. These results establish representation-informed diffusion sampling as a practical strategy for reinforcing semantic preservation and image consistency.
Pre-trained Models Succeed in Medical Imaging with Representation Similarity Degradation
Mar 11, 2025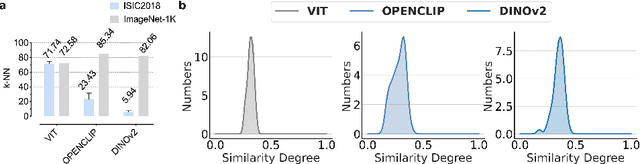
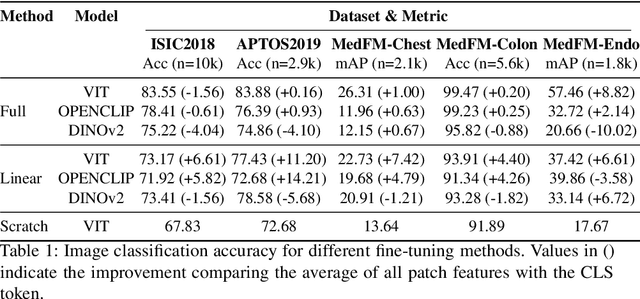
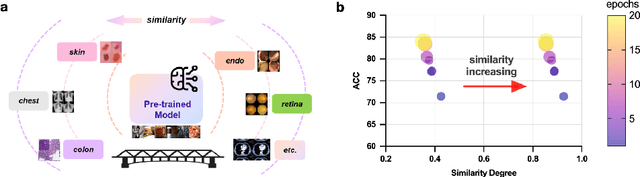
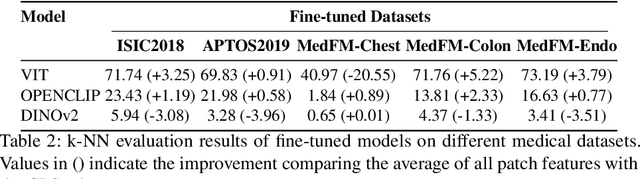
This paper investigates the critical problem of representation similarity evolution during cross-domain transfer learning, with particular focus on understanding why pre-trained models maintain effectiveness when adapted to medical imaging tasks despite significant domain gaps. The study establishes a rigorous problem definition centered on quantifying and analyzing representation similarity trajectories throughout the fine-tuning process, while carefully delineating the scope to encompass both medical image analysis and broader cross-domain adaptation scenarios. Our empirical findings reveal three critical discoveries: the potential existence of high-performance models that preserve both task accuracy and representation similarity to their pre-trained origins; a robust linear correlation between layer-wise similarity metrics and representation quality indicators; and distinct adaptation patterns that differentiate supervised versus self-supervised pre-training paradigms. The proposed similarity space framework not only provides mechanistic insights into knowledge transfer dynamics but also raises fundamental questions about optimal utilization of pre-trained models. These results advance our understanding of neural network adaptation processes while offering practical implications for transfer learning strategies that extend beyond medical imaging applications. The code will be available once accepted.
Keeping Representation Similarity in Finetuning for Medical Image Analysis
Mar 10, 2025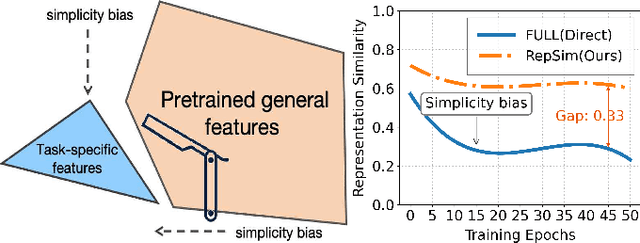
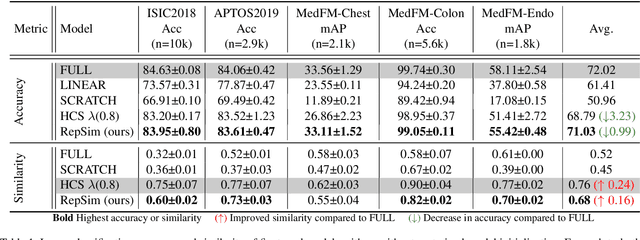
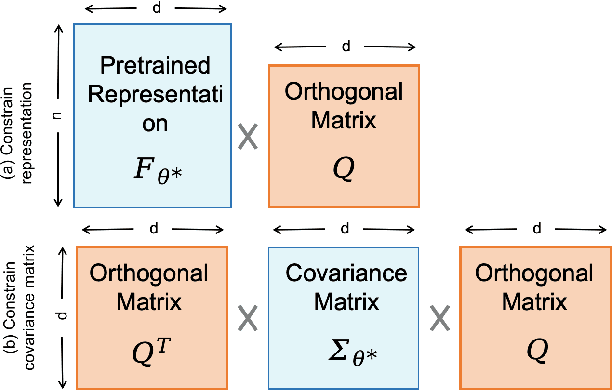
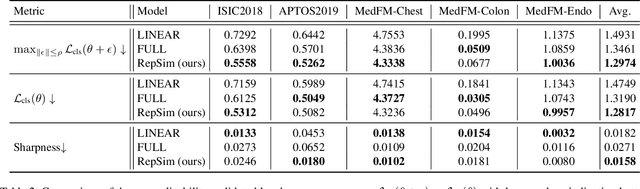
Foundation models pretrained on large-scale natural images have been widely used to adapt to medical image analysis through finetuning. This is largely attributed to pretrained representations capturing universal, robust, and generalizable features, which can be reutilized by downstream tasks. However, these representations are later found to gradually vanish during finetuning, accompanied by a degradation of foundation model's original abilities, e.g., generalizability. In this paper, we argue that pretrained representations can be well preserved while still effectively adapting to downstream tasks. We study this by proposing a new finetuning method RepSim, which minimizes the distance between pretrained and finetuned representations via constraining learnable orthogonal manifold based on similarity invariance. Compared to standard finetuning methods, e.g., full finetuning, our method improves representation similarity by over 30% while maintaining competitive accuracy, and reduces sharpness by 42% across five medical image classification datasets. The code will be released.
Towards Unifying Understanding and Generation in the Era of Vision Foundation Models: A Survey from the Autoregression Perspective
Oct 29, 2024


Autoregression in large language models (LLMs) has shown impressive scalability by unifying all language tasks into the next token prediction paradigm. Recently, there is a growing interest in extending this success to vision foundation models. In this survey, we review the recent advances and discuss future directions for autoregressive vision foundation models. First, we present the trend for next generation of vision foundation models, i.e., unifying both understanding and generation in vision tasks. We then analyze the limitations of existing vision foundation models, and present a formal definition of autoregression with its advantages. Later, we categorize autoregressive vision foundation models from their vision tokenizers and autoregression backbones. Finally, we discuss several promising research challenges and directions. To the best of our knowledge, this is the first survey to comprehensively summarize autoregressive vision foundation models under the trend of unifying understanding and generation. A collection of related resources is available at https://github.com/EmmaSRH/ARVFM.
Embedded Prompt Tuning: Towards Enhanced Calibration of Pretrained Models for Medical Images
Jul 02, 2024

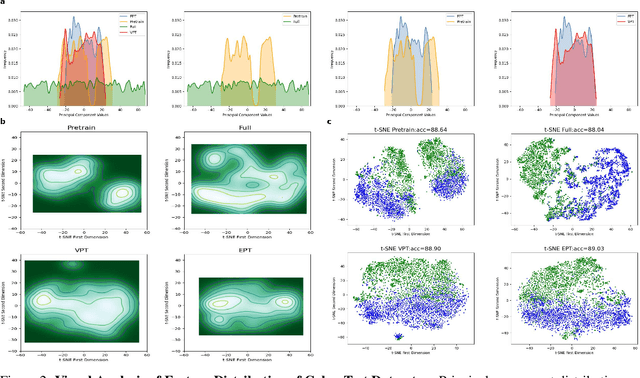

Foundation models pre-trained on large-scale data have been widely witnessed to achieve success in various natural imaging downstream tasks. Parameter-efficient fine-tuning (PEFT) methods aim to adapt foundation models to new domains by updating only a small portion of parameters in order to reduce computational overhead. However, the effectiveness of these PEFT methods, especially in cross-domain few-shot scenarios, e.g., medical image analysis, has not been fully explored. In this work, we facilitate the study of the performance of PEFT when adapting foundation models to medical image classification tasks. Furthermore, to alleviate the limitations of prompt introducing ways and approximation capabilities on Transformer architectures of mainstream prompt tuning methods, we propose the Embedded Prompt Tuning (EPT) method by embedding prompt tokens into the expanded channels. We also find that there are anomalies in the feature space distribution of foundation models during pre-training process, and prompt tuning can help mitigate this negative impact. To explain this phenomenon, we also introduce a novel perspective to understand prompt tuning: Prompt tuning is a distribution calibrator. And we support it by analyzing patch-wise scaling and feature separation operations contained in EPT. Our experiments show that EPT outperforms several state-of-the-art fine-tuning methods by a significant margin on few-shot medical image classification tasks, and completes the fine-tuning process within highly competitive time, indicating EPT is an effective PEFT method. The source code is available at github.com/zuwenqiang/EPT.