 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Prompt Tuning: Towards Enhanced Calibration of Pretrained Models for Medical Images
Paper and Code


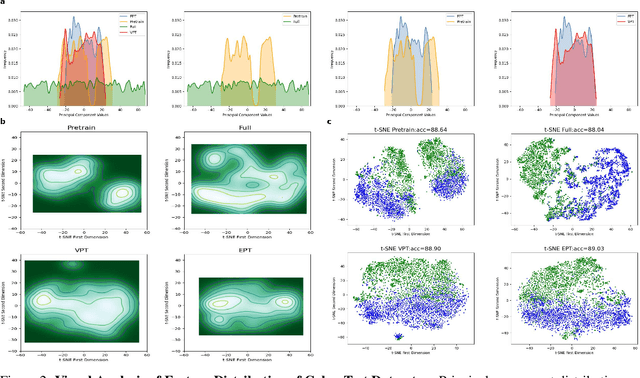

Foundation models pre-trained on large-scale data have been widely witnessed to achieve success in various natural imaging downstream tasks. Parameter-efficient fine-tuning (PEFT) methods aim to adapt foundation models to new domains by updating only a small portion of parameters in order to reduce computational overhead. However, the effectiveness of these PEFT methods, especially in cross-domain few-shot scenarios, e.g., medical image analysis, has not been fully explored. In this work, we facilitate the study of the performance of PEFT when adapting foundation models to medical image classification tasks. Furthermore, to alleviate the limitations of prompt introducing ways and approximation capabilities on Transformer architectures of mainstream prompt tuning methods, we propose the Embedded Prompt Tuning (EPT) method by embedding prompt tokens into the expanded channels. We also find that there are anomalies in the feature space distribution of foundation models during pre-training process, and prompt tuning can help mitigate this negative impact. To explain this phenomenon, we also introduce a novel perspective to understand prompt tuning: Prompt tuning is a distribution calibrator. And we support it by analyzing patch-wise scaling and feature separation operations contained in EPT. Our experiments show that EPT outperforms several state-of-the-art fine-tuning methods by a significant margin on few-shot medical image classification tasks, and completes the fine-tuning process within highly competitive time, indicating EPT is an effective PEFT method. The source code is available at github.com/zuwenqiang/EPT.