 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychēChat: An Empathic Framework Focused on Emotion Shift Tracking and Safety Risk Analysis in Psychological Counseling
Jan 18, 2026Large language models (LLMs) have demonstrated notable advancements in psychological counseling. However, existing models generally do not explicitly model seekers' emotion shifts across counseling sessions, a core focus in classical psychological schools. Moreover, how to align counselor models' responses with these emotion shifts while proactively mitigating safety risks remains underexplored. To bridge these gaps, we propose PsychēChat, which explicitly integrates emotion shift tracking and safety risk analysis for psychological counseling. Specifically, we employ interactive role-playing to synthesize counselor--seeker dialogues, incorporating two modules: Emotion Management Module, to capture seekers' current emotions and emotion shifts; and Risk Control Module, to anticipate seekers' subsequent reactions and identify potential risks. Furthermore, we introduce two modeling paradigms. The Agent Mode structures emotion management, risk control, and counselor responses into a collaborative multi-agent pipeline. The LLM Mode integrates these stages into a unified chain-of-thought for end-to-end inference, balancing efficiency and performance. Extensive experiments, including interactive scoring, dialogue-level evaluation, and human assessment, demonstrate that PsychēChat outperforms existing methods for emotional insight and safety control.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
Neural Network based Deep Transfer Learning for Cross-domain Dependency Parsing
Aug 08, 2019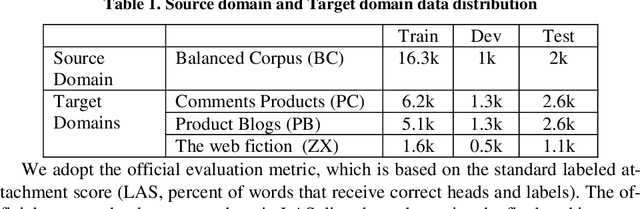
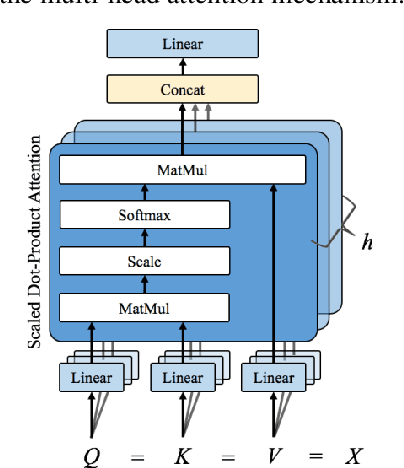

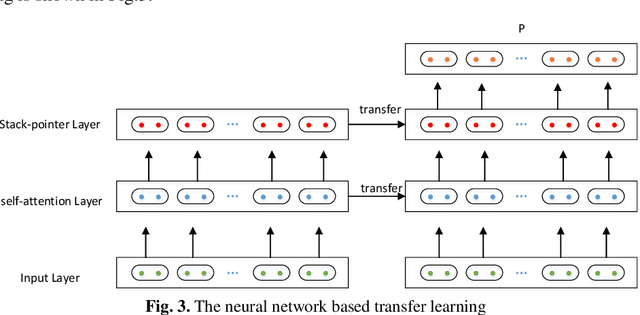
In this paper, we describe the details of the neural dependency parser sub-mitted by our team to the NLPCC 2019 Shared Task of Semi-supervised do-main adaptation subtask on Cross-domain Dependency Parsing. Our system is based on the stack-pointer networks(STACKPTR). Considering the im-portance of context, we utilize self-attention mechanism for the representa-tion vectors to capture the meaning of words. In addition, to adapt three dif-ferent domains, we utilize neural network based deep transfer learning which transfers the pre-trained partial network in the source domain to be a part of deep neural network in the three target domains (product comments, product blogs and web fiction) respectively. Results on the three target domains demonstrate that our model performs competitively.