 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Large Vision Language Models to be Good Few-shot Learners
Aug 21, 2024



Few-shot classification (FSC) is a fundamental yet challenging task in computer vision that involves recognizing novel classes from limited data. While previous methods have focused on enhancing visual features or incorporating additional modalities, Large Vision Language Models (LVLMs) offer a promising alternative due to their rich knowledge and strong visual perception. However, LVLMs risk learning specific response formats rather than effectively extracting useful information from support data in FSC tasks. In this paper, we investigate LVLMs' performance in FSC and identify key issues such as insufficient learning and the presence of severe positional biases. To tackle the above challenges, we adopt the meta-learning strategy to teach models "learn to learn". By constructing a rich set of meta-tasks for instruction fine-tuning, LVLMs enhance the ability to extract information from few-shot support data for classification. Additionally, we further boost LVLM's few-shot learning capabilities through label augmentation and candidate selection in the fine-tuning and inference stage, respectively. Label augmentation is implemented via a character perturbation strategy to ensure the model focuses on support information. Candidate selection leverages attribute descriptions to filter out unreliable candidates and simplify the task. Extensive experiments demonstrate that our approach achieves superior performance on both general and fine-grained datasets. Furthermore, our candidate selection strategy has been proven beneficial for training-free LVLMs.
Few-shot Adaptation of Multi-modal Foundation Models: A Survey
Jan 04, 2024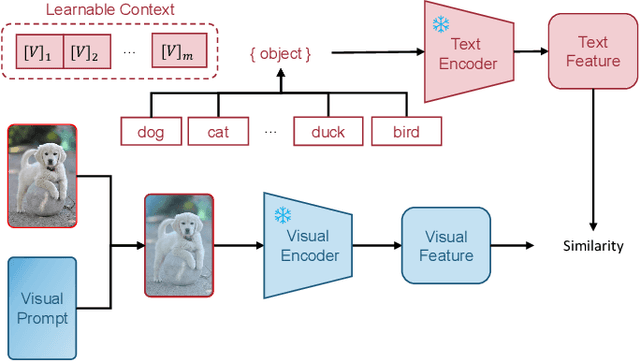
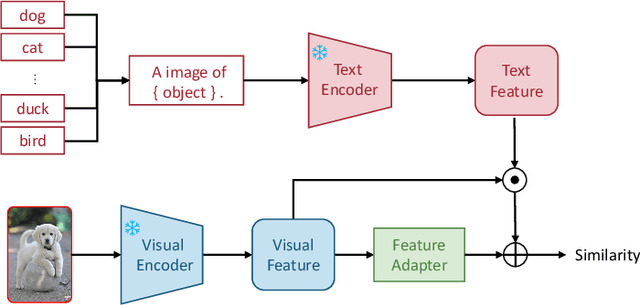
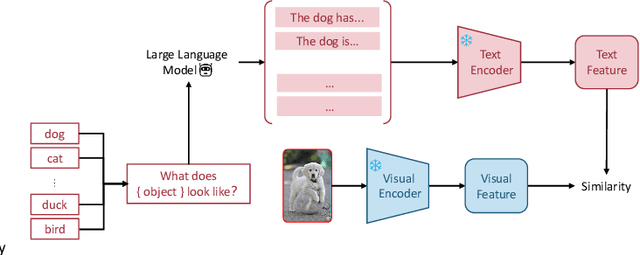
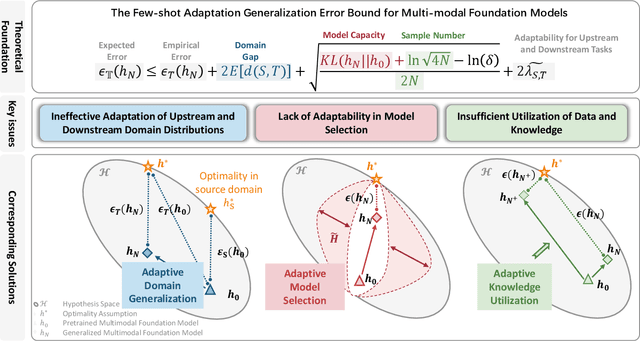
Multi-modal (vision-language) models, such as CLIP, are replacing traditional supervised pre-training models (e.g., ImageNet-based pre-training) as the new generation of visual foundation models. These models with robust and aligned semantic representations learned from billions of internet image-text pairs and can be applied to various downstream tasks in a zero-shot manner. However, in some fine-grained domains like medical imaging and remote sensing, the performance of multi-modal foundation models often leaves much to be desired. Consequently, many researchers have begun to explore few-shot adaptation methods for these models, gradually deriving three main technical approaches: 1) prompt-based methods, 2) adapter-based methods, and 3) external knowledge-based methods. Nevertheless, this rapidly developing field has produced numerous results without a comprehensive survey to systematically organize the research progress. Therefore, in this survey, we introduce and analyze the research advancements in few-shot adaptation methods for multi-modal models, summarizing commonly used datasets and experimental setups, and comparing the results of different methods. In addition, due to the lack of reliable theoretical support for existing methods, we derive the few-shot adaptation generalization error bound for multi-modal models. The theorem reveals that the generalization error of multi-modal foundation models is constrained by three factors: domain gap, model capacity, and sample size. Based on this, we propose three possible solutions from the following aspects: 1) adaptive domain generalization, 2) adaptive model selection, and 3) adaptive knowledge utilization.