 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Adaptation of Multi-modal Foundation Models: A Survey
Jan 04, 2024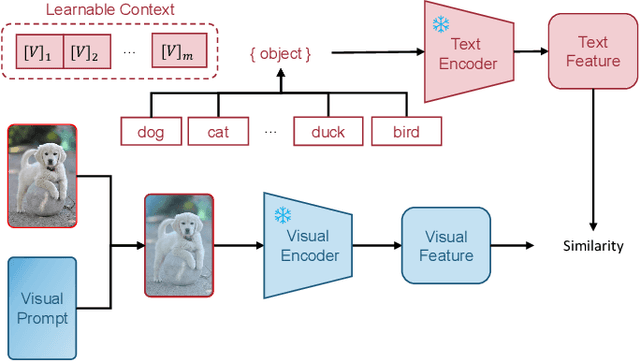
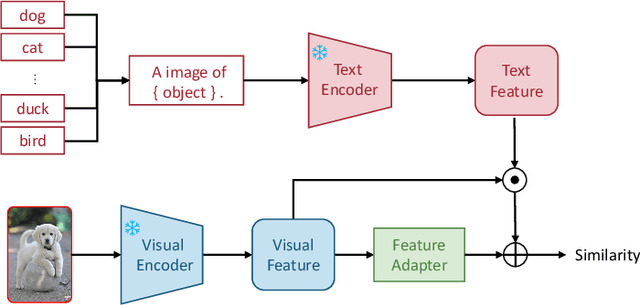
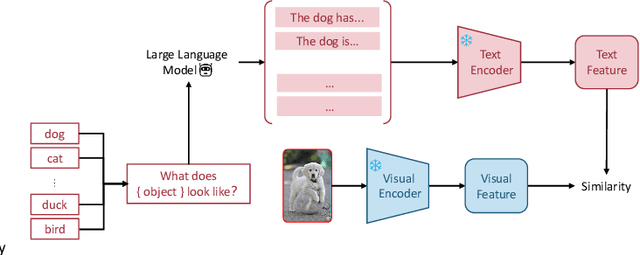
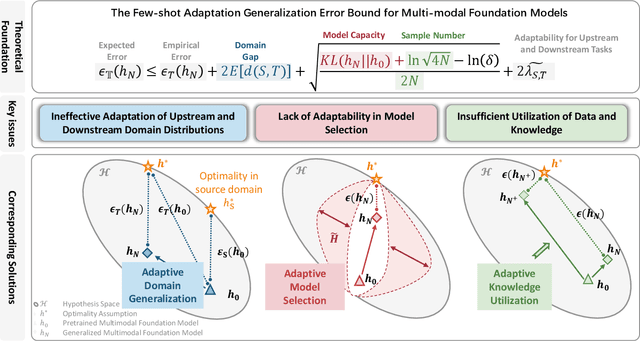
Multi-modal (vision-language) models, such as CLIP, are replacing traditional supervised pre-training models (e.g., ImageNet-based pre-training) as the new generation of visual foundation models. These models with robust and aligned semantic representations learned from billions of internet image-text pairs and can be applied to various downstream tasks in a zero-shot manner. However, in some fine-grained domains like medical imaging and remote sensing, the performance of multi-modal foundation models often leaves much to be desired. Consequently, many researchers have begun to explore few-shot adaptation methods for these models, gradually deriving three main technical approaches: 1) prompt-based methods, 2) adapter-based methods, and 3) external knowledge-based methods. Nevertheless, this rapidly developing field has produced numerous results without a comprehensive survey to systematically organize the research progress. Therefore, in this survey, we introduce and analyze the research advancements in few-shot adaptation methods for multi-modal models, summarizing commonly used datasets and experimental setups, and comparing the results of different methods. In addition, due to the lack of reliable theoretical support for existing methods, we derive the few-shot adaptation generalization error bound for multi-modal models. The theorem reveals that the generalization error of multi-modal foundation models is constrained by three factors: domain gap, model capacity, and sample size. Based on this, we propose three possible solutions from the following aspects: 1) adaptive domain generalization, 2) adaptive model selection, and 3) adaptive knowledge utilization.
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
Jun 19, 2023General-purpose foundation models have become increasingly important in the field of artificial intelligence. While self-supervised learning (SSL) and Masked Image Modeling (MIM) have led to promising results in building such foundation models for remote sensing, these models primarily learn low-level features, require annotated data for fine-tuning, and not applicable for retrieval and zero-shot applications due to the lack of language understanding. In response to these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics, as well as aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling, converting heterogeneous annotations based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion, and further incorporating UAV imagery, resulting a 12xlarger pretraining dataset. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, k-NN classification, few-shot classification, image-text retrieval, and object counting. Evaluations on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, show that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP outperform previous SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets.