 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
OmniDiT: Extending Diffusion Transformer to Omni-VTON Framework
Mar 20, 2026Despite the rapid advancement of Virtual Try-On (VTON) and Try-Off (VTOFF) technologies, existing VTON methods face challenges with fine-grained detail preservation, generalization to complex scenes, complicated pipeline, and efficient inference. To tackle these problems, we propose OmniDiT, an omni Virtual Try-On framework based on the Diffusion Transformer, which combines try-on and try-off tasks into one unified model. Specifically, we first establish a self-evolving data curation pipeline to continuously produce data, and construct a large VTON dataset Omni-TryOn, which contains over 380k diverse and high-quality garment-model-tryon image pairs and detailed text prompts. Then, we employ the token concatenation and design an adaptive position encoding to effectively incorporate multiple reference conditions. To relieve the bottleneck of long sequence computation, we are the first to introduce Shifted Window Attention into the diffusion model, thus achieving a linear complexity. To remedy the performance degradation caused by local window attention, we utilize multiple timestep prediction and an alignment loss to improve generation fidelity. Experiments reveal that, under various complex scenes, our method achieves the best performance in both the model-free VTON and VTOFF tasks and a performance comparable to current SOTA methods in the model-based VTON task.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
WDFFU-Mamba: A Wavelet-guided Dual-attention Feature Fusion Mamba for Breast Tumor Segmentation in Ultrasound Images
Dec 19, 2025Breast ultrasound (BUS) image segmentation plays a vital role in assisting clinical diagnosis and early tumor screening. However, challenges such as speckle noise, imaging artifacts, irregular lesion morphology, and blurred boundaries severely hinder accurate segmentation. To address these challenges, this work aims to design a robust and efficient model capable of automatically segmenting breast tumors in BUS images.We propose a novel segmentation network named WDFFU-Mamba, which integrates wavelet-guided enhancement and dual-attention feature fusion within a U-shaped Mamba architecture. A Wavelet-denoised High-Frequency-guided Feature (WHF) module is employed to enhance low-level representations through noise-suppressed high-frequency cues. A Dual Attention Feature Fusion (DAFF) module is also introduced to effectively merge skip-connected and semantic features, improving contextual consistency.Extensive experiments on two public BUS datasets demonstrate that WDFFU-Mamba achieves superior segmentation accuracy, significantly outperforming existing methods in terms of Dice coefficient and 95th percentile Hausdorff Distance (HD95).The combination of wavelet-domain enhancement and attention-based fusion greatly improves both the accuracy and robustness of BUS image segmentation, while maintaining computational efficiency.The proposed WDFFU-Mamba model not only delivers strong segmentation performance but also exhibits desirable generalization ability across datasets, making it a promising solution for real-world clinical applications in breast tumor ultrasound analysis.
ScaleADFG: Affordance-based Dexterous Functional Grasping via Scalable Dataset
Nov 12, 2025Dexterous functional tool-use grasping is essential for effective robotic manipulation of tools. However, existing approaches face significant challenges in efficiently constructing large-scale datasets and ensuring generalizability to everyday object scales. These issues primarily arise from size mismatches between robotic and human hands, and the diversity in real-world object scales. To address these limitations, we propose the ScaleADFG framework, which consists of a fully automated dataset construction pipeline and a lightweight grasp generation network. Our dataset introduce an affordance-based algorithm to synthesize diverse tool-use grasp configurations without expert demonstrations, allowing flexible object-hand size ratios and enabling large robotic hands (compared to human hands) to grasp everyday objects effectively. Additionally, we leverage pre-trained models to generate extensive 3D assets and facilitate efficient retrieval of object affordances. Our dataset comprising five object categories, each containing over 1,000 unique shapes with 15 scale variations. After filtering, the dataset includes over 60,000 grasps for each 2 dexterous robotic hands. On top of this dataset, we train a lightweight, single-stage grasp generation network with a notably simple loss design, eliminating the need for post-refinement. This demonstrates the critical importance of large-scale datasets and multi-scale object variant for effective training. Extensive experiments in simulation and on real robot confirm that the ScaleADFG framework exhibits strong adaptability to objects of varying scales, enhancing functional grasp stability, diversity, and generalizability. Moreover, our network exhibits effective zero-shot transfer to real-world objects. Project page is available at https://sizhe-wang.github.io/ScaleADFG_webpage
Kolmogorov Arnold Informed neural network: A physics-informed deep learning framework for solving PDEs based on Kolmogorov Arnold Networks
Jun 16, 2024
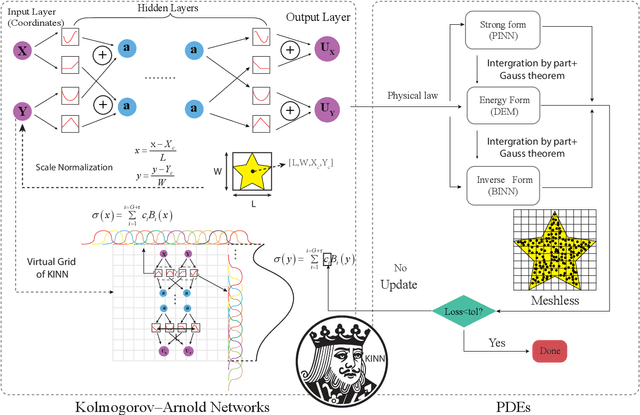
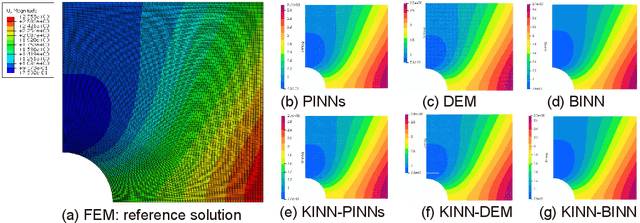
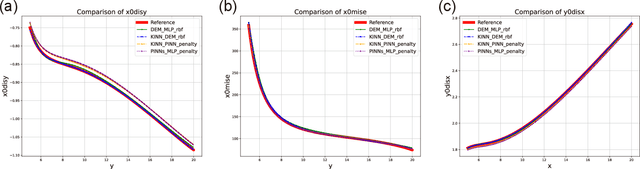
AI for partial differential equations (PDEs) has garnered significant attention, particularly with the emergence of Physics-informed neural networks (PINNs). The recent advent of Kolmogorov-Arnold Network (KAN) indicates that there is potential to revisit and enhance the previously MLP-based PINNs. Compared to MLPs, KANs offer interpretability and require fewer parameters. PDEs can be described in various forms, such as strong form, energy form, and inverse form. While mathematically equivalent, these forms are not computationally equivalent, making the exploration of different PDE formulations significant in computational physics. Thus, we propose different PDE forms based on KAN instead of MLP, termed Kolmogorov-Arnold-Informed Neural Network (KINN). We systematically compare MLP and KAN in various numerical examples of PDEs, including multi-scale, singularity, stress concentration, nonlinear hyperelasticity, heterogeneous, and complex geometry problems. Our results demonstrate that KINN significantly outperforms MLP in terms of accuracy and convergence speed for numerous PDEs in computational solid mechanics, except for the complex geometry problem. This highlights KINN's potential for more efficient and accurate PDE solutions in AI for PDEs.
EVE: Efficient Vision-Language Pre-training with Masked Prediction and Modality-Aware MoE
Aug 23, 2023
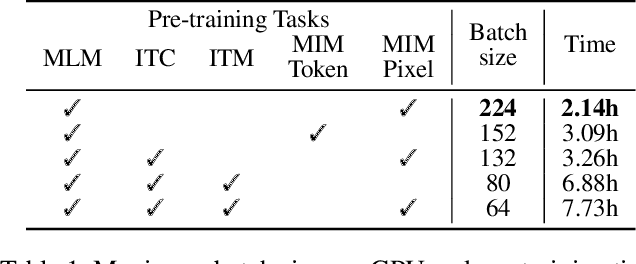

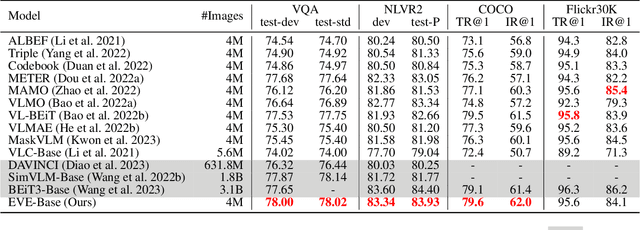
Building scalable vision-language models to learn from diverse, multimodal data remains an open challenge. In this paper, we introduce an Efficient Vision-languagE foundation model, namely EVE, which is one unified multimodal Transformer pre-trained solely by one unified pre-training task. Specifically, EVE encodes both vision and language within a shared Transformer network integrated with modality-aware sparse Mixture-of-Experts (MoE) modules, which capture modality-specific information by selectively switching to different experts. To unify pre-training tasks of vision and language, EVE performs masked signal modeling on image-text pairs to reconstruct masked signals, i.e., image pixels and text tokens, given visible signals. This simple yet effective pre-training objective accelerates training by 3.5x compared to the model pre-trained with Image-Text Contrastive and Image-Text Matching losses. Owing to the combination of the unified architecture and pre-training task, EVE is easy to scale up, enabling better downstream performance with fewer resources and faster training speed. Despite its simplicity, EVE achieves state-of-the-art performance on various vision-language downstream tasks, including visual question answering, visual reasoning, and image-text retrieval.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023



Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.
Learning Tri-mode Grasping for Ambidextrous Robot Picking
Feb 28, 2023Object picking in cluttered scenes is a widely investigated field of robot manipulation, however, ambidextrous robot picking is still an important and challenging issue. We found the fusion of different prehensile actions (grasp and suction) can expand the range of objects that can be picked by robot, and the fusion of prehensile action and nonprehensile action (push) can expand the picking space of ambidextrous robot. In this paper, we propose a Push-Grasp-Suction (PGS) tri-mode grasping learning network for ambidextrous robot picking through the fusion of different prehensile actions and the fusion of prehensile action and nonprehensile aciton. The prehensile branch of PGS takes point clouds as input, and the 6-DoF picking configuration of grasp and suction in cluttered scenes are generated by multi-task point cloud learning. The nonprehensile branch with depth image input generates instance segmentation map and push configuration, cooperating with the prehensile actions to complete the picking of objects out of single-arm space. PGS generalizes well in real scene and achieves state-of-the-art picking performance.
DCM: Deep complementary energy method based on the principle of minimum complementary energy
Feb 13, 2023The principle of minimum potential and complementary energy are the most important variational principles in solid mechanics. The deep energy method (DEM), which has received much attention, is based on the principle of minimum potential energy, but it lacks the important form of minimum complementary energy. To fill the gap, we propose a deep complementary energy method (DCM) based on the principle of minimum complementary energy. The output function of DCM is the stress function that naturally satisfies the equilibrium equation. We extend the proposed DCM algorithm to DCM-Plus (DCM-P), adding the terms that naturally satisfy the biharmonic equation in the Airy stress function. We combine operator learning with physical equations and propose a deep complementary energy operator method (DCM-O), including branch net, trunk net, basis net, and particular net. DCM-O first combines existing high-fidelity numerical results to train DCM-O through data. Then the complementary energy is used to train the branch net and trunk net in DCM-O. To analyze DCM performance, we present the numerical result of the most common stress functions, the Prandtl and Airy stress function. The proposed method DCM is used to model the representative mechanical problems with different types of boundary conditions. We compare DCM with the existing PINNs and DEM algorithms. The result shows the advantage of the proposed DCM is suitable for dealing with problems of dominated displacement boundary conditions, which is proved by mathematical derivations, as well as with numerical experiments. DCM-P and DCM-O can improve the accuracy and efficiency of DCM. DCM is an essential supplementary energy form to the deep energy method. Operator learning based on the energy method can balance data and physical equations well, giving computational mechanics broad research prospects.