 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025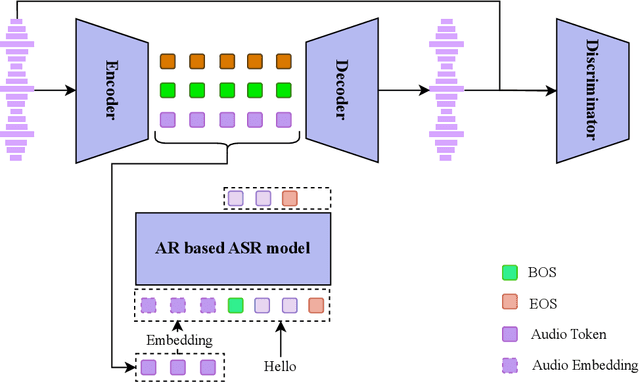

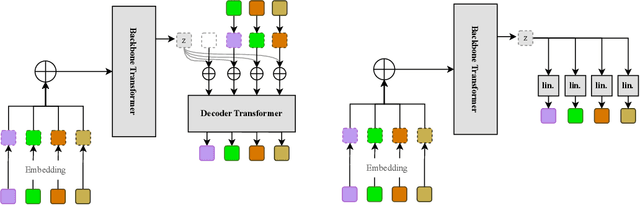
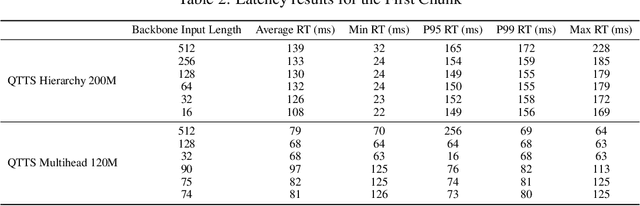
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Computer-aided Recognition and Assessment of a Porous Bioelastomer on Ultrasound Images for Regenerative Medicine Applications
Jan 31, 2022Biodegradable elastic scaffolds have attracted more and more attention in the field of soft tissue repair and tissue engineering. These scaffolds made of porous bioelastomers support tissue ingrowth along with their own degradation. It is necessary to develop a computer-aided analyzing method based on ultrasound images to identify the degradation performance of the scaffold, not only to obviate the need to do destructive testing, but also to monitor the scaffold's degradation and tissue ingrowth over time. It is difficult using a single traditional image processing algorithm to extract continuous and accurate contour of a porous bioelastomer. This paper proposes a joint algorithm for the bioelastomer's contour detection and a texture feature extraction method for monitoring the degradation behavior of the bioelastomer. Mean-shift clustering method is used to obtain the bioelastomer's and native tissue's clustering feature information. Then the OTSU image binarization method automatically selects the optimal threshold value to convert the grayscale ultrasound image into a binary image. The Canny edge detector is used to extract the complete bioelastomer's contour. The first-order and second-order statistical features of texture are extracted. The proposed joint algorithm not only achieves the ideal extraction of the bioelastomer's contours in ultrasound images, but also gives valuable feedback of the degradation behavior of the bioelastomer at the implant site based on the changes of texture characteristics and contour area. The preliminary results of this study suggest that the proposed computer-aided image processing techniques have values and potentials in the non-invasive analysis of tissue scaffolds in vivo based on ultrasound images and may help tissue engineers evaluate the tissue scaffold's degradation and cellular ingrowth progress and improve the scaffold designs.
IQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022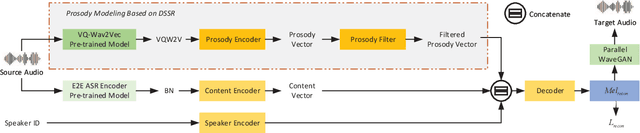
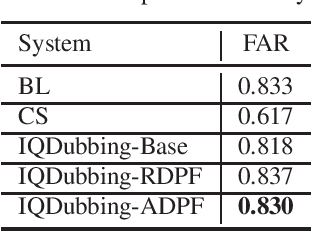
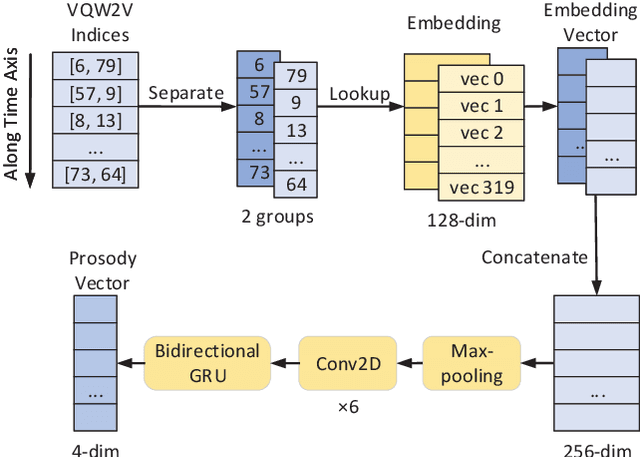
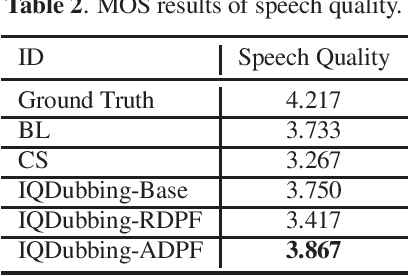
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.