 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022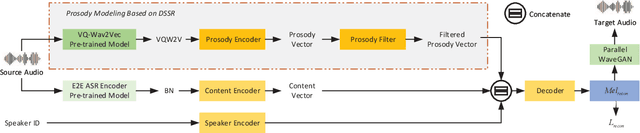
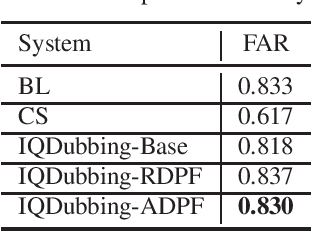
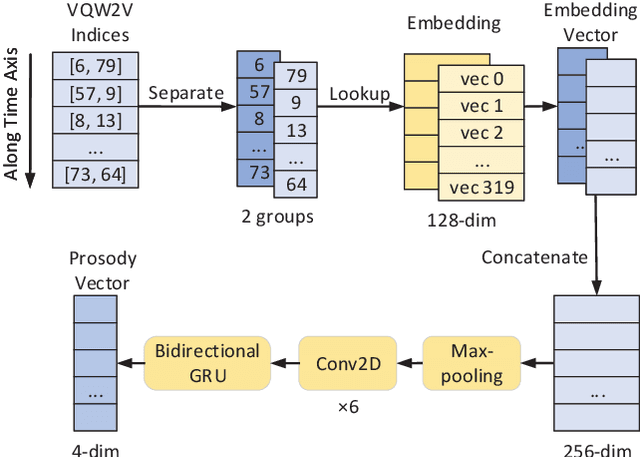
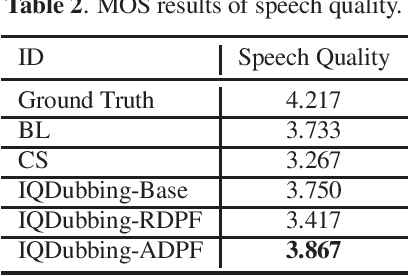
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.