 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-robust voice conversion with domain adversarial training
Jan 26, 2022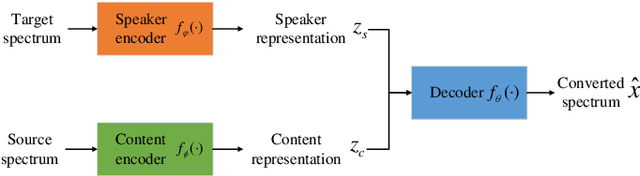
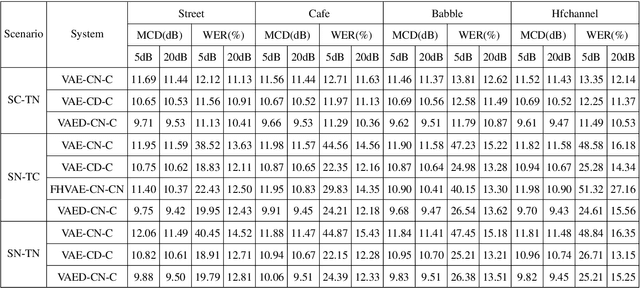
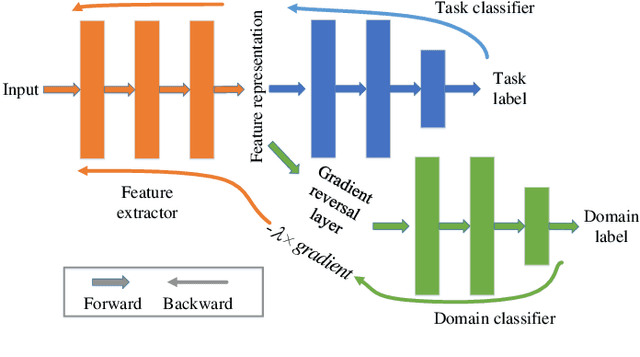
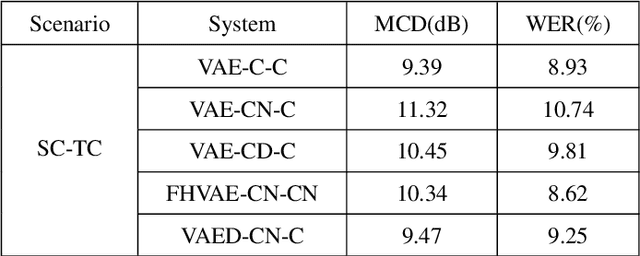
Voice conversion has made great progress in the past few years under the studio-quality test scenario in terms of speech quality and speaker similarity. However, in real applications, test speech from source speaker or target speaker can be corrupted by various environment noises, which seriously degrade the speech quality and speaker similarity. In this paper, we propose a novel encoder-decoder based noise-robust voice conversion framework, which consists of a speaker encoder, a content encoder, a decoder, and two domain adversarial neural networks. Specifically, we integrate disentangling speaker and content representation technique with domain adversarial training technique. Domain adversarial training makes speaker representations and content representations extracted by speaker encoder and content encoder from clean speech and noisy speech in the same space, respectively. In this way, the learned speaker and content representations are noise-invariant. Therefore, the two noise-invariant representations can be taken as input by the decoder to predict the clean converted spectrum. The experimental results demonstrate that our proposed method can synthesize clean converted speech under noisy test scenarios, where the source speech and target speech can be corrupted by seen or unseen noise types during the training process. Additionally, both speech quality and speaker similarity are improved.
IQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022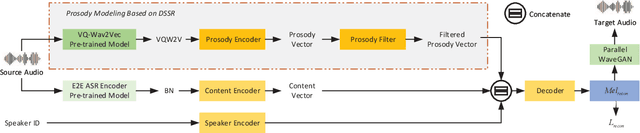
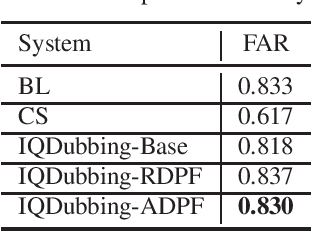
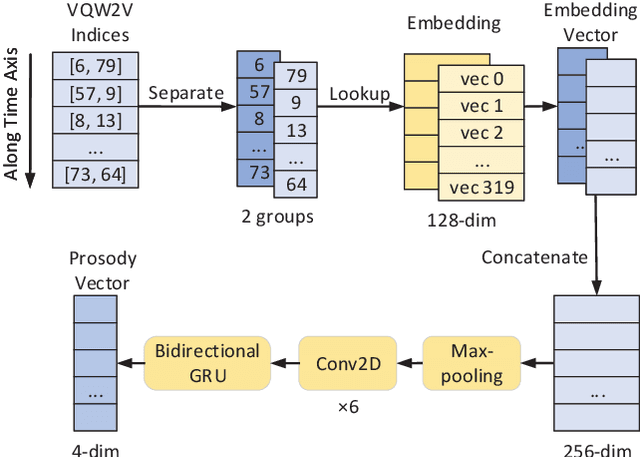
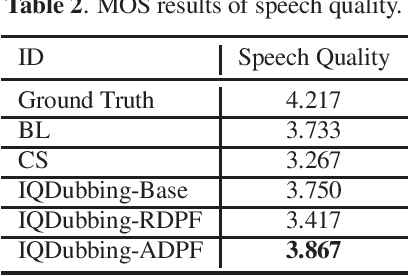
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.
One-shot Voice Conversion For Style Transfer Based On Speaker Adaptation
Nov 24, 2021One-shot style transfer is a challenging task, since training on one utterance makes model extremely easy to over-fit to training data and causes low speaker similarity and lack of expressiveness. In this paper, we build on the recognition-synthesis framework and propose a one-shot voice conversion approach for style transfer based on speaker adaptation. First, a speaker normalization module is adopted to remove speaker-related information in bottleneck features extracted by ASR. Second, we adopt weight regularization in the adaptation process to prevent over-fitting caused by using only one utterance from target speaker as training data. Finally, to comprehensively decouple the speech factors, i.e., content, speaker, style, and transfer source style to the target, a prosody module is used to extract prosody representation. Experiments show that our approach is superior to the state-of-the-art one-shot VC systems in terms of style and speaker similarity; additionally, our approach also maintains good speech quality.
Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion
Jun 26, 2021
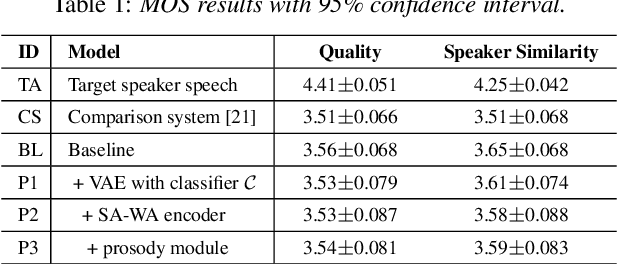
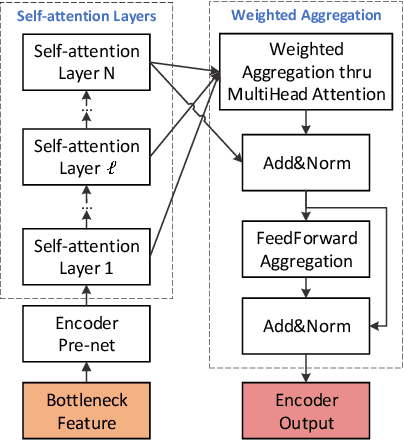
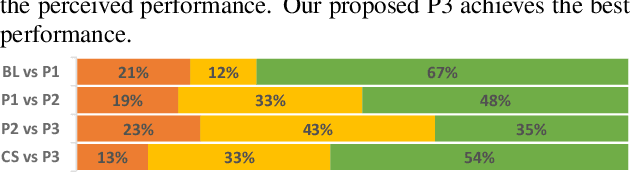
Current voice conversion (VC) methods can successfully convert timbre of the audio. As modeling source audio's prosody effectively is a challenging task, there are still limitations of transferring source style to the converted speech. This study proposes a source style transfer method based on recognition-synthesis framework. Previously in speech generation task, prosody can be modeled explicitly with prosodic features or implicitly with a latent prosody extractor. In this paper, taking advantages of both, we model the prosody in a hybrid manner, which effectively combines explicit and implicit methods in a proposed prosody module. Specifically, prosodic features are used to explicit model prosody, while VAE and reference encoder are used to implicitly model prosody, which take Mel spectrum and bottleneck feature as input respectively. Furthermore, adversarial training is introduced to remove speaker-related information from the VAE outputs, avoiding leaking source speaker information while transferring style. Finally, we use a modified self-attention based encoder to extract sentential context from bottleneck features, which also implicitly aggregates the prosodic aspects of source speech from the layered representations. Experiments show that our approach is superior to the baseline and a competitive system in terms of style transfer; meanwhile, the speech quality and speaker similarity are well maintained.
Improving robustness of one-shot voice conversion with deep discriminative speaker encoder
Jun 19, 2021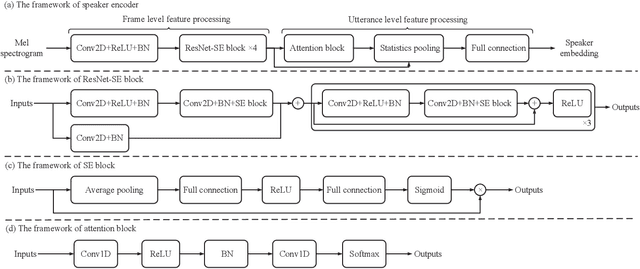
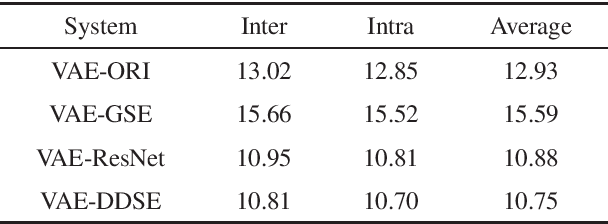
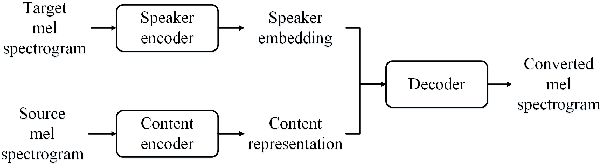

One-shot voice conversion has received significant attention since only one utterance from source speaker and target speaker respectively is required. Moreover, source speaker and target speaker do not need to be seen during training. However, available one-shot voice conversion approaches are not stable for unseen speakers as the speaker embedding extracted from one utterance of an unseen speaker is not reliable. In this paper, we propose a deep discriminative speaker encoder to extract speaker embedding from one utterance more effectively. Specifically, the speaker encoder first integrates residual network and squeeze-and-excitation network to extract discriminative speaker information in frame level by modeling frame-wise and channel-wise interdependence in features. Then attention mechanism is introduced to further emphasize speaker related information via assigning different weights to frame level speaker information. Finally a statistic pooling layer is used to aggregate weighted frame level speaker information to form utterance level speaker embedding. The experimental results demonstrate that our proposed speaker encoder can improve the robustness of one-shot voice conversion for unseen speakers and outperforms baseline systems in terms of speech quality and speaker similarity.