 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving robustness of one-shot voice conversion with deep discriminative speaker encoder
Paper and Code
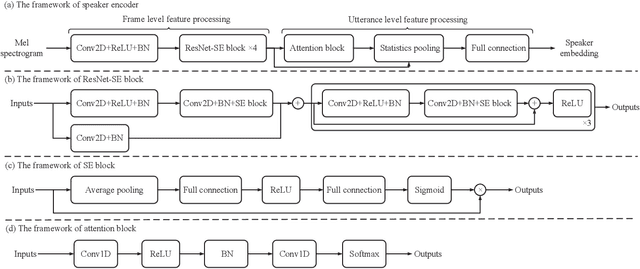
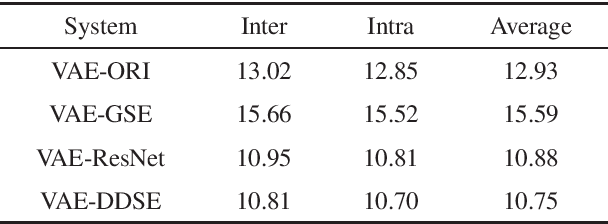
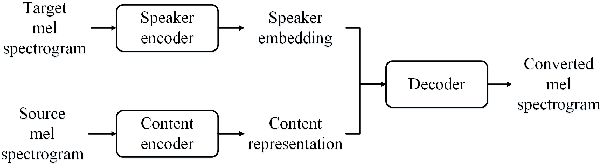

One-shot voice conversion has received significant attention since only one utterance from source speaker and target speaker respectively is required. Moreover, source speaker and target speaker do not need to be seen during training. However, available one-shot voice conversion approaches are not stable for unseen speakers as the speaker embedding extracted from one utterance of an unseen speaker is not reliable. In this paper, we propose a deep discriminative speaker encoder to extract speaker embedding from one utterance more effectively. Specifically, the speaker encoder first integrates residual network and squeeze-and-excitation network to extract discriminative speaker information in frame level by modeling frame-wise and channel-wise interdependence in features. Then attention mechanism is introduced to further emphasize speaker related information via assigning different weights to frame level speaker information. Finally a statistic pooling layer is used to aggregate weighted frame level speaker information to form utterance level speaker embedding. The experimental results demonstrate that our proposed speaker encoder can improve the robustness of one-shot voice conversion for unseen speakers and outperforms baseline systems in terms of speech quality and speaker similarity.