 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022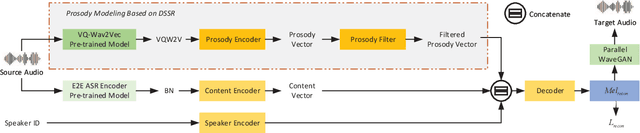
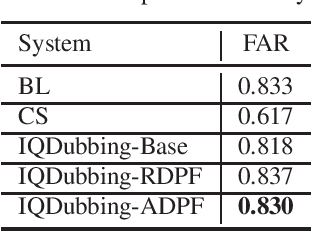
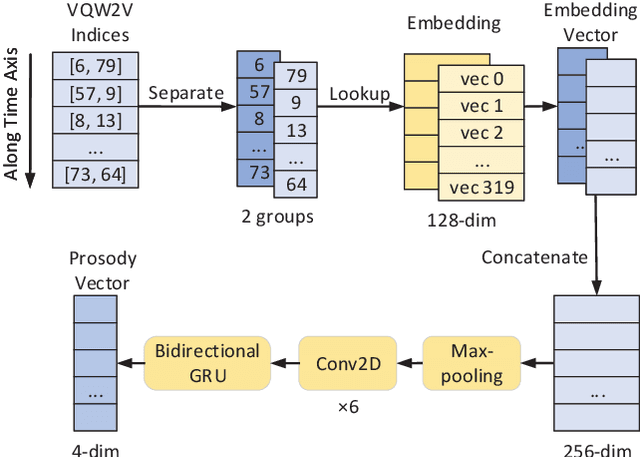
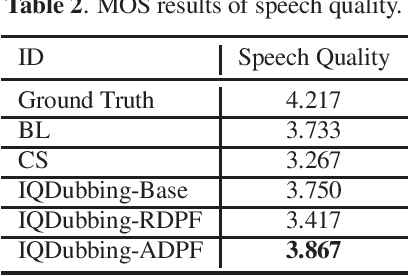
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.
Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion
Jun 26, 2021
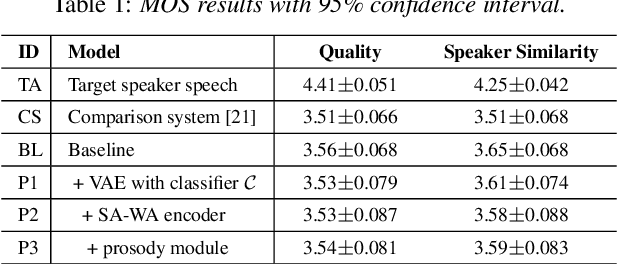
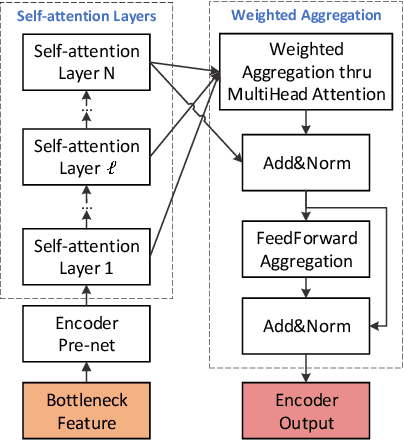
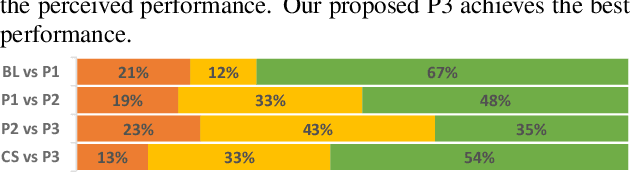
Current voice conversion (VC) methods can successfully convert timbre of the audio. As modeling source audio's prosody effectively is a challenging task, there are still limitations of transferring source style to the converted speech. This study proposes a source style transfer method based on recognition-synthesis framework. Previously in speech generation task, prosody can be modeled explicitly with prosodic features or implicitly with a latent prosody extractor. In this paper, taking advantages of both, we model the prosody in a hybrid manner, which effectively combines explicit and implicit methods in a proposed prosody module. Specifically, prosodic features are used to explicit model prosody, while VAE and reference encoder are used to implicitly model prosody, which take Mel spectrum and bottleneck feature as input respectively. Furthermore, adversarial training is introduced to remove speaker-related information from the VAE outputs, avoiding leaking source speaker information while transferring style. Finally, we use a modified self-attention based encoder to extract sentential context from bottleneck features, which also implicitly aggregates the prosodic aspects of source speech from the layered representations. Experiments show that our approach is superior to the baseline and a competitive system in terms of style transfer; meanwhile, the speech quality and speaker similarity are well maintained.