 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired analogical mixture prototypes for few-shot class-incremental learning
Feb 26, 2025Few-shot class-incremental learning (FSCIL) poses significant challenges for artificial neural networks due to the need to efficiently learn from limited data while retaining knowledge of previously learned tasks. Inspired by the brain's mechanisms for categorization and analogical learning, we propose a novel approach called Brain-inspired Analogical Mixture Prototypes (BAMP). BAMP has three components: mixed prototypical feature learning, statistical analogy, and soft voting. Starting from a pre-trained Vision Transformer (ViT), mixed prototypical feature learning represents each class using a mixture of prototypes and fine-tunes these representations during the base session. The statistical analogy calibrates the mean and covariance matrix of prototypes for new classes according to similarity to the base classes, and computes classification score with Mahalanobis distance. Soft voting combines both merits of statistical analogy and an off-shelf FSCIL method. Our experiments on benchmark datasets demonstrate that BAMP outperforms state-of-the-art on both traditional big start FSCIL setting and challenging small start FSCIL setting. The study suggests that brain-inspired analogical mixture prototypes can alleviate catastrophic forgetting and over-fitting problems in FSCIL.
FAS-assisted Wireless Powered Communication Systems
Feb 03, 2024

Fluid Antenna System (FAS) is recognized as a promising technology for enhancing communication performance. In this context, we explored the potential of FAS-assisted wireless powered communication systems. Specifically, the transmitter, equipped with FAS, harvests the radio frequency (RF) signal from a power beacon and utilizes the harvested energy for data transmission to the receiver. To evaluate the performance of the considered systems, we derive both the analytical and asymptotic expressions of the outage probability. Simulation results indicate that the diversity of the considered network closely aligns with the number of ports. Besides, it is also revealed that the port selection criteria based solely on single-hop configurations yield a diversity order of only one.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023



Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.
DVGG: Deep Variational Grasp Generation for Dextrous Manipulation
Nov 21, 2022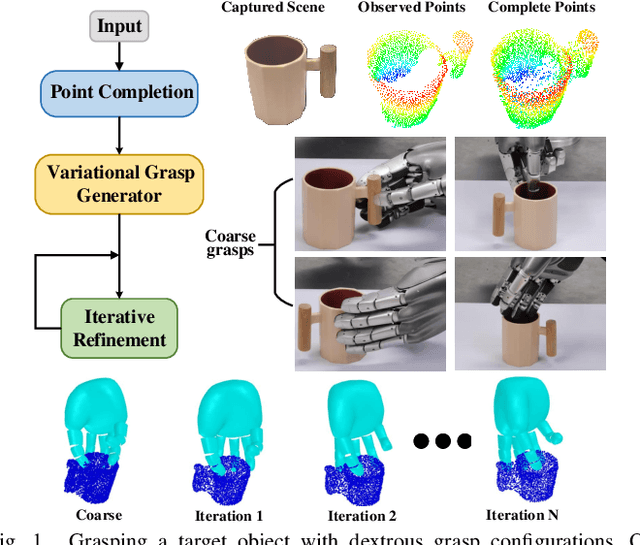

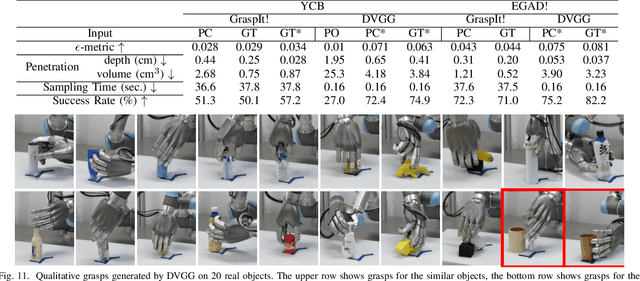
Grasping with anthropomorphic robotic hands involves much more hand-object interactions compared to parallel-jaw grippers. Modeling hand-object interactions is essential to the study of multi-finger hand dextrous manipulation. This work presents DVGG, an efficient grasp generation network that takes single-view observation as input and predicts high-quality grasp configurations for unknown objects. In general, our generative model consists of three components: 1) Point cloud completion for the target object based on the partial observation; 2) Diverse sets of grasps generation given the complete point cloud; 3) Iterative grasp pose refinement for physically plausible grasp optimization. To train our model, we build a large-scale grasping dataset that contains about 300 common object models with 1.5M annotated grasps in simulation. Experiments in simulation show that our model can predict robust grasp poses with a wide variety and high success rate. Real robot platform experiments demonstrate that the model trained on our dataset performs well in the real world. Remarkably, our method achieves a grasp success rate of 70.7\% for novel objects in the real robot platform, which is a significant improvement over the baseline methods.
GPR: Grasp Pose Refinement Network for Cluttered Scenes
May 18, 2021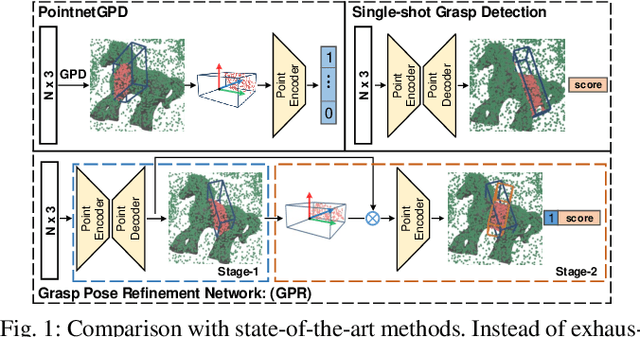
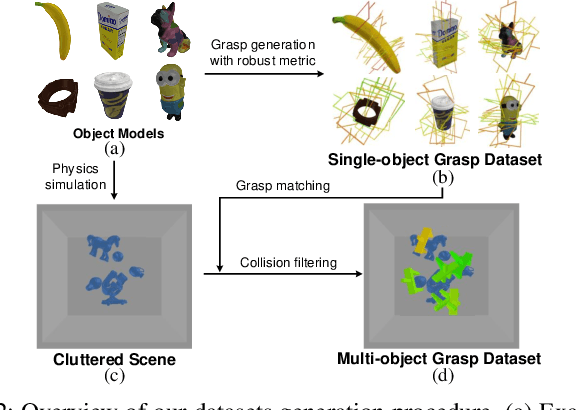
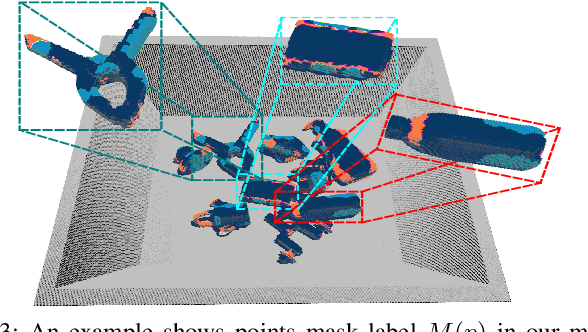
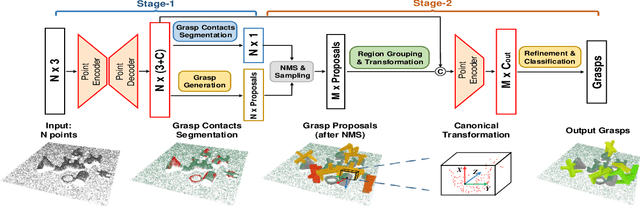
Object grasping in cluttered scenes is a widely investigated field of robot manipulation. Most of the current works focus on estimating grasp pose from point clouds based on an efficient single-shot grasp detection network. However, due to the lack of geometry awareness of the local grasping area, it may cause severe collisions and unstable grasp configurations. In this paper, we propose a two-stage grasp pose refinement network which detects grasps globally while fine-tuning low-quality grasps and filtering noisy grasps locally. Furthermore, we extend the 6-DoF grasp with an extra dimension as grasp width which is critical for collisionless grasping in cluttered scenes. It takes a single-view point cloud as input and predicts dense and precise grasp configurations. To enhance the generalization ability, we build a synthetic single-object grasp dataset including 150 commodities of various shapes, and a multi-object cluttered scene dataset including 100k point clouds with robust, dense grasp poses and mask annotations. Experiments conducted on Yumi IRB-1400 Robot demonstrate that the model trained on our dataset performs well in real environments and outperforms previous methods by a large margin.
Deep Domain Adaptive Object Detection: a Survey
Feb 17, 2020
Deep learning (DL) based object detection has achieved great progress. These methods typically assume that large amount of labeled training data is available, and training and test data are drawn from an identical distribution. However, the two assumptions are not always hold in practice. Deep domain adaptive object detection (DDAOD) has emerged as a new learning paradigm to address the above mentioned challenges. This paper aims to review the state-of-the-art progress on deep domain adaptive object detection approaches. Firstly, we introduce briefly the basic concepts of deep domain adaptation. Secondly, the deep domain adaptive detectors are classified into four categories and detailed descriptions of representative methods in each category are provided. Finally, insights for future research trend are presented.
Unsupervised Image-generation Enhanced Adaptation for Object Detection in Thermal images
Feb 17, 2020
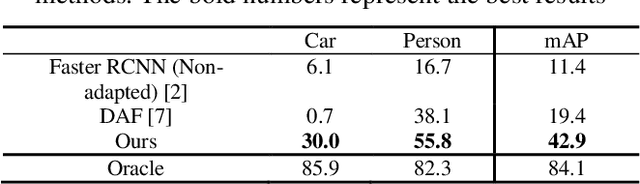

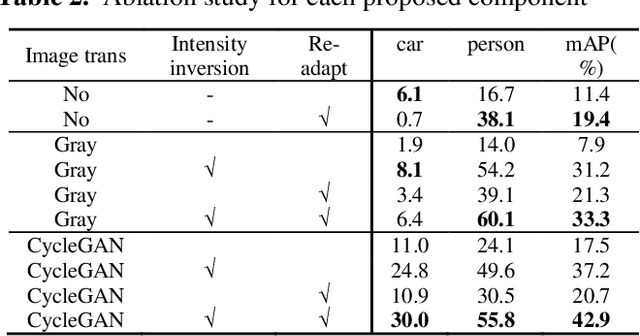
Object detection in thermal images is an important computer vision task and has many applications such as unmanned vehicles, robotics, surveillance and night vision. Deep learning based detectors have achieved major progress, which usually need large amount of labelled training data. However, labelled data for object detection in thermal images is scarce and expensive to collect. How to take advantage of the large number labelled visible images and adapt them into thermal image domain, is expected to solve. This paper proposes an unsupervised image-generation enhanced adaptation method for object detection in thermal images. To reduce the gap between visible domain and thermal domain, the proposed method manages to generate simulated fake thermal images that are similar to the target images, and preserves the annotation information of the visible source domain. The image generation includes a CycleGAN based image-to-image translation and an intensity inversion transformation. Generated fake thermal images are used as renewed source domain. And then the off-the-shelf Domain Adaptive Faster RCNN is utilized to reduce the gap between generated intermediate domain and the thermal target domain. Experiments demonstrate the effectiveness and superiority of the proposed method.