 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Tri-mode Grasping for Ambidextrous Robot Picking
Feb 28, 2023Object picking in cluttered scenes is a widely investigated field of robot manipulation, however, ambidextrous robot picking is still an important and challenging issue. We found the fusion of different prehensile actions (grasp and suction) can expand the range of objects that can be picked by robot, and the fusion of prehensile action and nonprehensile action (push) can expand the picking space of ambidextrous robot. In this paper, we propose a Push-Grasp-Suction (PGS) tri-mode grasping learning network for ambidextrous robot picking through the fusion of different prehensile actions and the fusion of prehensile action and nonprehensile aciton. The prehensile branch of PGS takes point clouds as input, and the 6-DoF picking configuration of grasp and suction in cluttered scenes are generated by multi-task point cloud learning. The nonprehensile branch with depth image input generates instance segmentation map and push configuration, cooperating with the prehensile actions to complete the picking of objects out of single-arm space. PGS generalizes well in real scene and achieves state-of-the-art picking performance.
GPR: Grasp Pose Refinement Network for Cluttered Scenes
May 18, 2021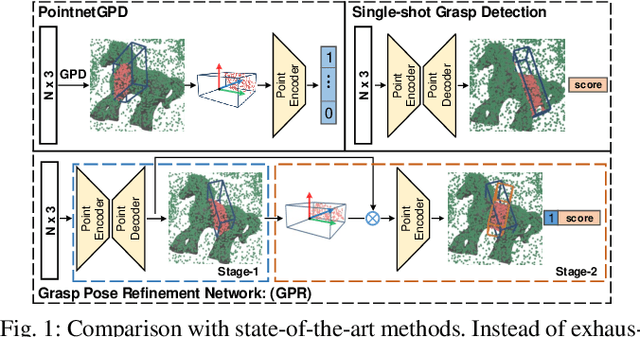
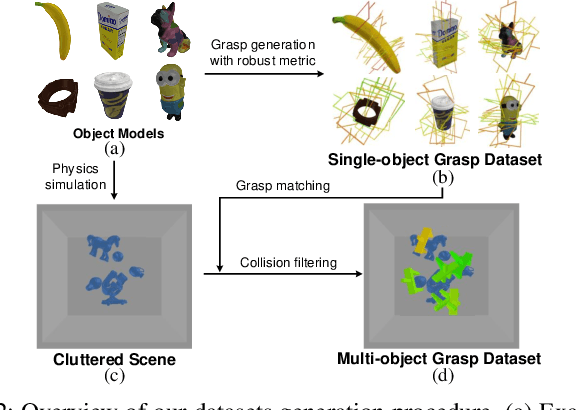
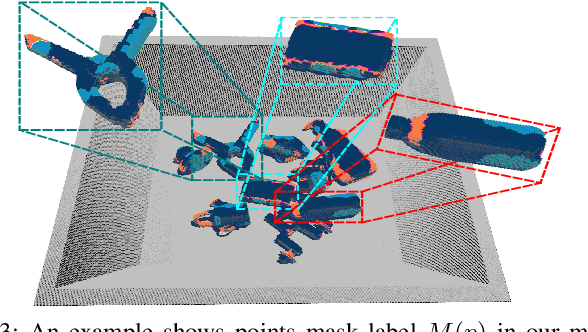
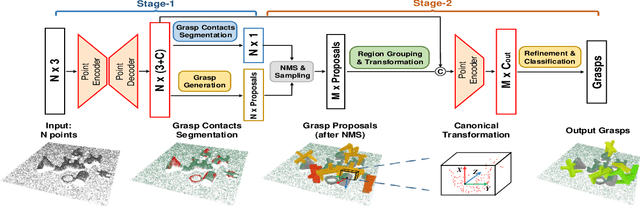
Object grasping in cluttered scenes is a widely investigated field of robot manipulation. Most of the current works focus on estimating grasp pose from point clouds based on an efficient single-shot grasp detection network. However, due to the lack of geometry awareness of the local grasping area, it may cause severe collisions and unstable grasp configurations. In this paper, we propose a two-stage grasp pose refinement network which detects grasps globally while fine-tuning low-quality grasps and filtering noisy grasps locally. Furthermore, we extend the 6-DoF grasp with an extra dimension as grasp width which is critical for collisionless grasping in cluttered scenes. It takes a single-view point cloud as input and predicts dense and precise grasp configurations. To enhance the generalization ability, we build a synthetic single-object grasp dataset including 150 commodities of various shapes, and a multi-object cluttered scene dataset including 100k point clouds with robust, dense grasp poses and mask annotations. Experiments conducted on Yumi IRB-1400 Robot demonstrate that the model trained on our dataset performs well in real environments and outperforms previous methods by a large margin.
Deep Domain Adaptive Object Detection: a Survey
Feb 17, 2020
Deep learning (DL) based object detection has achieved great progress. These methods typically assume that large amount of labeled training data is available, and training and test data are drawn from an identical distribution. However, the two assumptions are not always hold in practice. Deep domain adaptive object detection (DDAOD) has emerged as a new learning paradigm to address the above mentioned challenges. This paper aims to review the state-of-the-art progress on deep domain adaptive object detection approaches. Firstly, we introduce briefly the basic concepts of deep domain adaptation. Secondly, the deep domain adaptive detectors are classified into four categories and detailed descriptions of representative methods in each category are provided. Finally, insights for future research trend are presented.
Unsupervised Image-generation Enhanced Adaptation for Object Detection in Thermal images
Feb 17, 2020
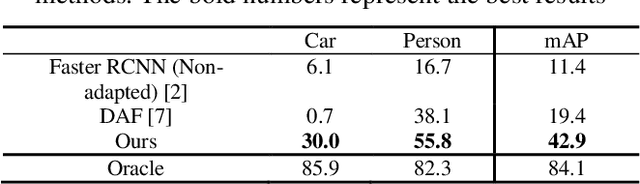

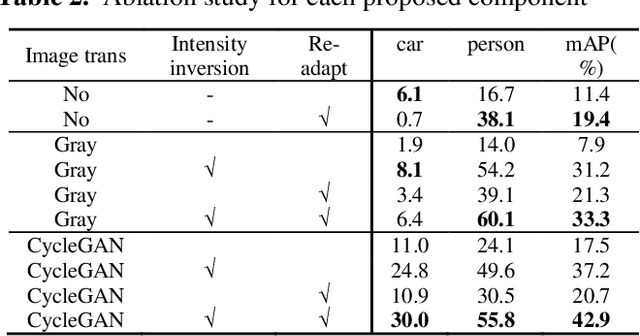
Object detection in thermal images is an important computer vision task and has many applications such as unmanned vehicles, robotics, surveillance and night vision. Deep learning based detectors have achieved major progress, which usually need large amount of labelled training data. However, labelled data for object detection in thermal images is scarce and expensive to collect. How to take advantage of the large number labelled visible images and adapt them into thermal image domain, is expected to solve. This paper proposes an unsupervised image-generation enhanced adaptation method for object detection in thermal images. To reduce the gap between visible domain and thermal domain, the proposed method manages to generate simulated fake thermal images that are similar to the target images, and preserves the annotation information of the visible source domain. The image generation includes a CycleGAN based image-to-image translation and an intensity inversion transformation. Generated fake thermal images are used as renewed source domain. And then the off-the-shelf Domain Adaptive Faster RCNN is utilized to reduce the gap between generated intermediate domain and the thermal target domain. Experiments demonstrate the effectiveness and superiority of the proposed method.