 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Grasp Pose Refinement Network for Cluttered Scenes
Paper and Code
May 18, 2021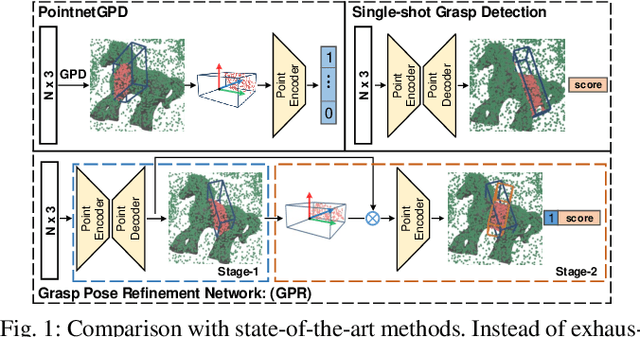
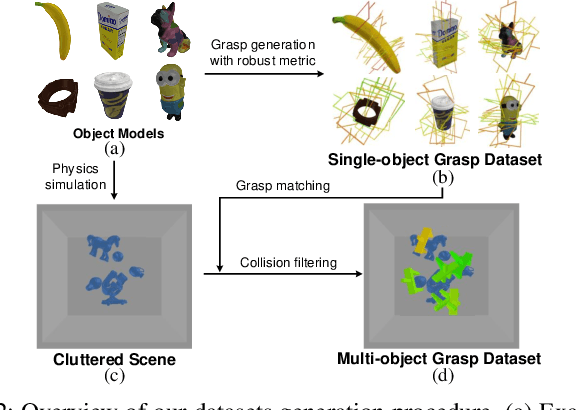
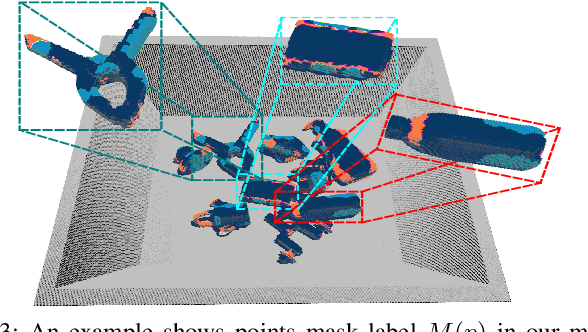
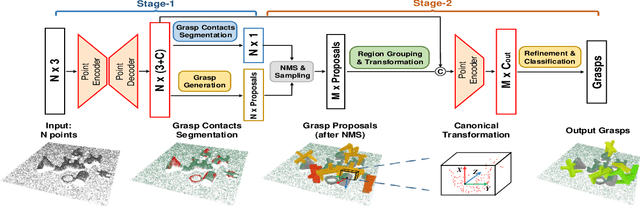
Object grasping in cluttered scenes is a widely investigated field of robot manipulation. Most of the current works focus on estimating grasp pose from point clouds based on an efficient single-shot grasp detection network. However, due to the lack of geometry awareness of the local grasping area, it may cause severe collisions and unstable grasp configurations. In this paper, we propose a two-stage grasp pose refinement network which detects grasps globally while fine-tuning low-quality grasps and filtering noisy grasps locally. Furthermore, we extend the 6-DoF grasp with an extra dimension as grasp width which is critical for collisionless grasping in cluttered scenes. It takes a single-view point cloud as input and predicts dense and precise grasp configurations. To enhance the generalization ability, we build a synthetic single-object grasp dataset including 150 commodities of various shapes, and a multi-object cluttered scene dataset including 100k point clouds with robust, dense grasp poses and mask annotations. Experiments conducted on Yumi IRB-1400 Robot demonstrate that the model trained on our dataset performs well in real environments and outperforms previous methods by a large margin.