 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiloBot: A Programming Language for Deploying Perception-Guided Industrial Manipulators at Scale
Sep 05, 2024We would like industrial robots to handle unstructured environments with cameras and perception pipelines. In contrast to traditional industrial robots that replay offline-crafted trajectories, online behavior planning is required for these perception-guided industrial applications. Aside from perception and planning algorithms, deploying perception-guided manipulators also requires substantial effort in integration. One approach is writing scripts in a traditional language (such as Python) to construct the planning problem and perform integration with other algorithmic modules & external devices. While scripting in Python is feasible for a handful of robots and applications, deploying perception-guided manipulation at scale (e.g., more than 10000 robot workstations in over 2000 customer sites) becomes intractable. To resolve this challenge, we propose a Domain-Specific Language (DSL) for perception-guided manipulation applications. To scale up the deployment,our DSL provides: 1) an easily accessible interface to construct & solve a sub-class of Task and Motion Planning (TAMP) problems that are important in practical applications; and 2) a mechanism to implement flexible control flow to perform integration and address customized requirements of distinct industrial application. Combined with an intuitive graphical programming frontend, our DSL is mainly used by machine operators without coding experience in traditional programming languages. Within hours of training, operators are capable of orchestrating interesting sophisticated manipulation behaviors with our DSL. Extensive practical deployments demonstrate the efficacy of our method.
DVGG: Deep Variational Grasp Generation for Dextrous Manipulation
Nov 21, 2022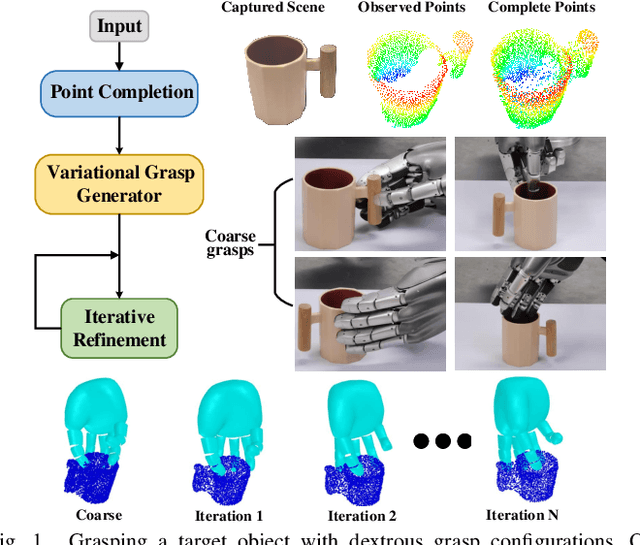

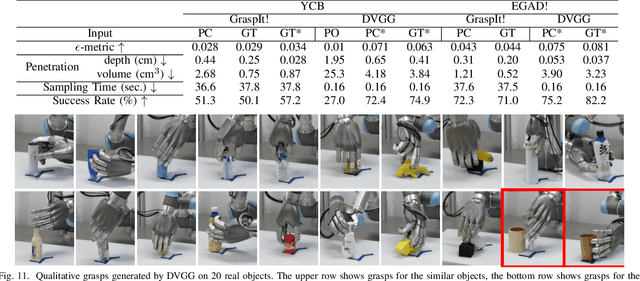
Grasping with anthropomorphic robotic hands involves much more hand-object interactions compared to parallel-jaw grippers. Modeling hand-object interactions is essential to the study of multi-finger hand dextrous manipulation. This work presents DVGG, an efficient grasp generation network that takes single-view observation as input and predicts high-quality grasp configurations for unknown objects. In general, our generative model consists of three components: 1) Point cloud completion for the target object based on the partial observation; 2) Diverse sets of grasps generation given the complete point cloud; 3) Iterative grasp pose refinement for physically plausible grasp optimization. To train our model, we build a large-scale grasping dataset that contains about 300 common object models with 1.5M annotated grasps in simulation. Experiments in simulation show that our model can predict robust grasp poses with a wide variety and high success rate. Real robot platform experiments demonstrate that the model trained on our dataset performs well in the real world. Remarkably, our method achieves a grasp success rate of 70.7\% for novel objects in the real robot platform, which is a significant improvement over the baseline methods.
GPR: Grasp Pose Refinement Network for Cluttered Scenes
May 18, 2021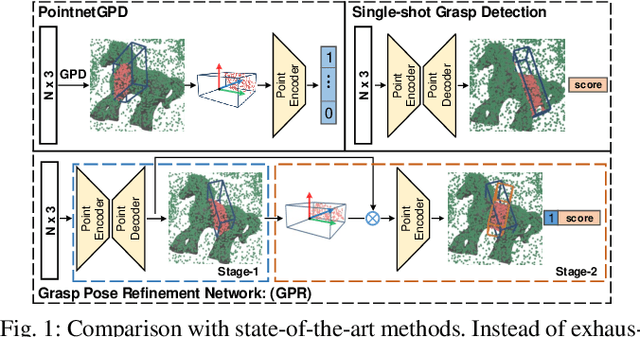
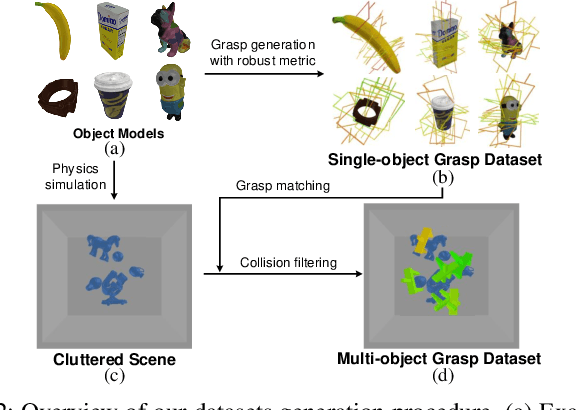
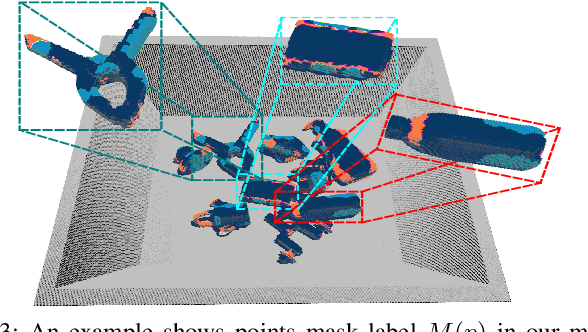
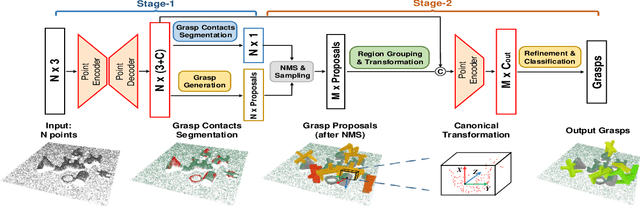
Object grasping in cluttered scenes is a widely investigated field of robot manipulation. Most of the current works focus on estimating grasp pose from point clouds based on an efficient single-shot grasp detection network. However, due to the lack of geometry awareness of the local grasping area, it may cause severe collisions and unstable grasp configurations. In this paper, we propose a two-stage grasp pose refinement network which detects grasps globally while fine-tuning low-quality grasps and filtering noisy grasps locally. Furthermore, we extend the 6-DoF grasp with an extra dimension as grasp width which is critical for collisionless grasping in cluttered scenes. It takes a single-view point cloud as input and predicts dense and precise grasp configurations. To enhance the generalization ability, we build a synthetic single-object grasp dataset including 150 commodities of various shapes, and a multi-object cluttered scene dataset including 100k point clouds with robust, dense grasp poses and mask annotations. Experiments conducted on Yumi IRB-1400 Robot demonstrate that the model trained on our dataset performs well in real environments and outperforms previous methods by a large margin.