 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVGG: Deep Variational Grasp Generation for Dextrous Manipulation
Paper and Code
Nov 21, 2022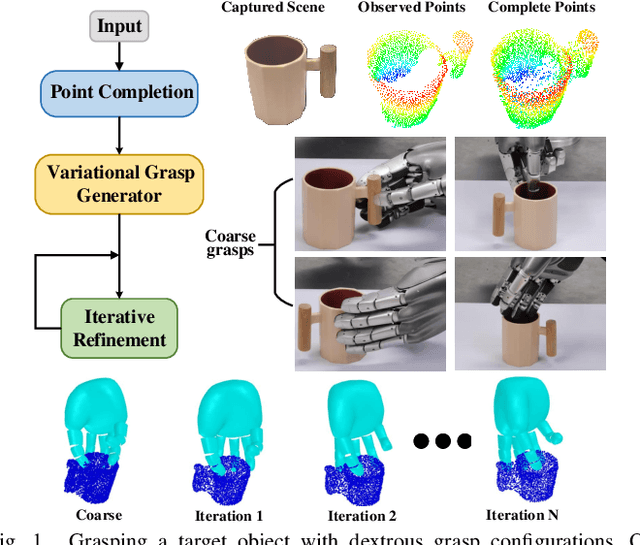

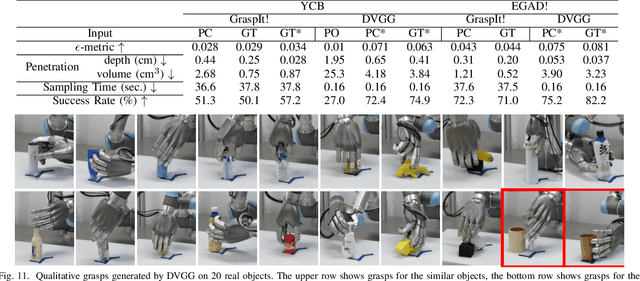
Grasping with anthropomorphic robotic hands involves much more hand-object interactions compared to parallel-jaw grippers. Modeling hand-object interactions is essential to the study of multi-finger hand dextrous manipulation. This work presents DVGG, an efficient grasp generation network that takes single-view observation as input and predicts high-quality grasp configurations for unknown objects. In general, our generative model consists of three components: 1) Point cloud completion for the target object based on the partial observation; 2) Diverse sets of grasps generation given the complete point cloud; 3) Iterative grasp pose refinement for physically plausible grasp optimization. To train our model, we build a large-scale grasping dataset that contains about 300 common object models with 1.5M annotated grasps in simulation. Experiments in simulation show that our model can predict robust grasp poses with a wide variety and high success rate. Real robot platform experiments demonstrate that the model trained on our dataset performs well in the real world. Remarkably, our method achieves a grasp success rate of 70.7\% for novel objects in the real robot platform, which is a significant improvement over the baseline methods.