 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
Nov 25, 2024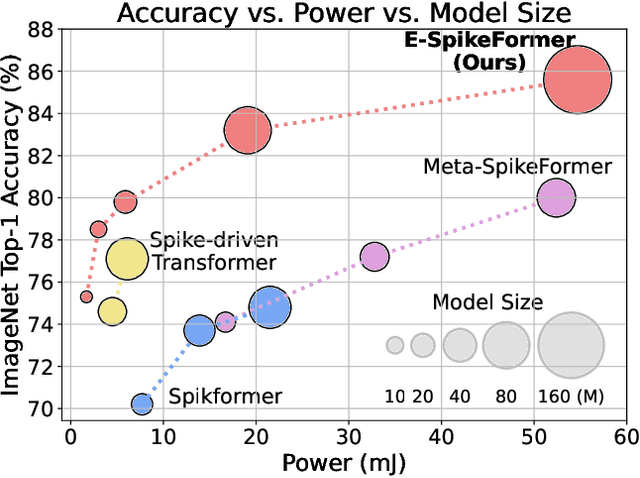
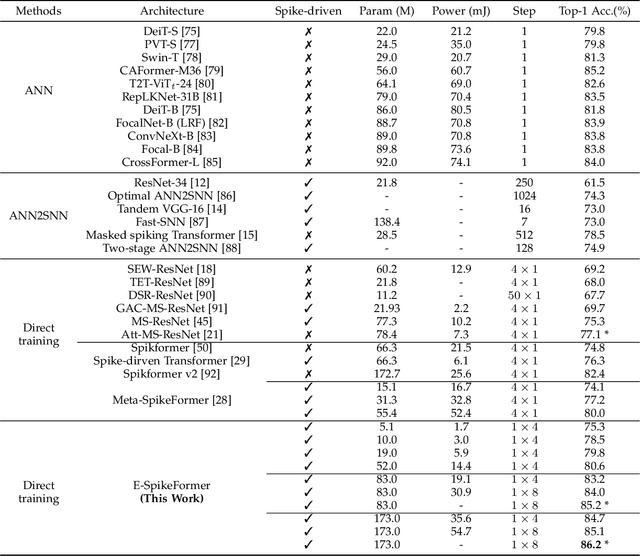
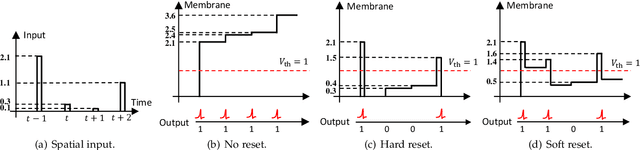
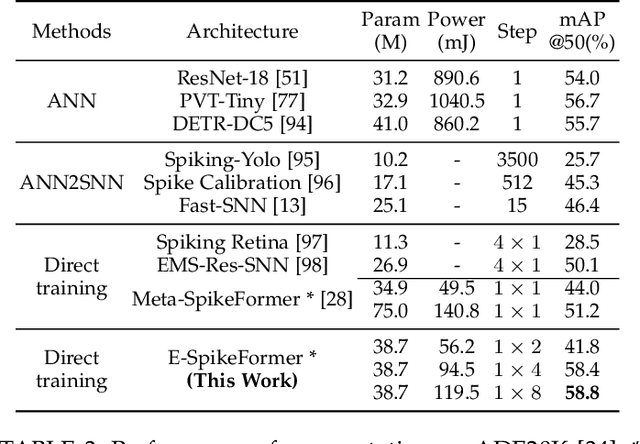
The ambition of brain-inspired Spiking Neural Networks (SNNs) is to become a low-power alternative to traditional Artificial Neural Networks (ANNs). This work addresses two major challenges in realizing this vision: the performance gap between SNNs and ANNs, and the high training costs of SNNs. We identify intrinsic flaws in spiking neurons caused by binary firing mechanisms and propose a Spike Firing Approximation (SFA) method using integer training and spike-driven inference. This optimizes the spike firing pattern of spiking neurons, enhancing efficient training, reducing power consumption, improving performance, enabling easier scaling, and better utilizing neuromorphic chips. We also develop an efficient spike-driven Transformer architecture and a spike-masked autoencoder to prevent performance degradation during SNN scaling. On ImageNet-1k, we achieve state-of-the-art top-1 accuracy of 78.5\%, 79.8\%, 84.0\%, and 86.2\% with models containing 10M, 19M, 83M, and 173M parameters, respectively. For instance, the 10M model outperforms the best existing SNN by 7.2\% on ImageNet, with training time acceleration and inference energy efficiency improved by 4.5$\times$ and 3.9$\times$, respectively. We validate the effectiveness and efficiency of the proposed method across various tasks, including object detection, semantic segmentation, and neuromorphic vision tasks. This work enables SNNs to match ANN performance while maintaining the low-power advantage, marking a significant step towards SNNs as a general visual backbone. Code is available at https://github.com/BICLab/Spike-Driven-Transformer-V3.
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Apr 03, 2024


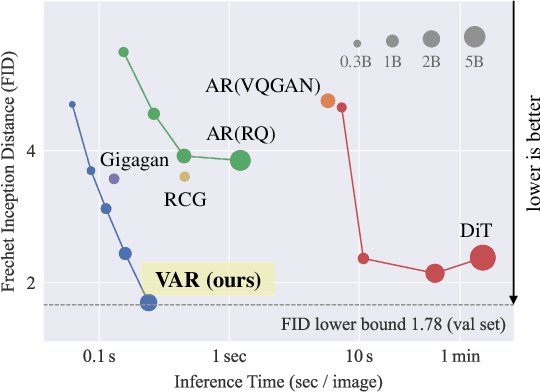
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.80, inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket
Jan 04, 2024Spiking Neural Networks (SNNs), known for their biologically plausible architecture, face the challenge of limited performance. The self-attention mechanism, which is the cornerstone of the high-performance Transformer and also a biologically inspired structure, is absent in existing SNNs. To this end, we explore the potential of leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self-Attention (SSA) and Spiking Transformer (Spikformer). The SSA mechanism eliminates the need for softmax and captures the sparse visual feature employing spike-based Query, Key, and Value. This sparse computation without multiplication makes SSA efficient and energy-saving. Further, we develop a Spiking Convolutional Stem (SCS) with supplementary convolutional layers to enhance the architecture of Spikformer. The Spikformer enhanced with the SCS is referred to as Spikformer V2. To train larger and deeper Spikformer V2, we introduce a pioneering exploration of Self-Supervised Learning (SSL) within the SNN. Specifically, we pre-train Spikformer V2 with masking and reconstruction style inspired by the mainstream self-supervised Transformer, and then finetune the Spikformer V2 on the image classification on ImageNet. Extensive experiments show that Spikformer V2 outperforms other previous surrogate training and ANN2SNN methods. An 8-layer Spikformer V2 achieves an accuracy of 80.38% using 4 time steps, and after SSL, a 172M 16-layer Spikformer V2 reaches an accuracy of 81.10% with just 1 time step. To the best of our knowledge, this is the first time that the SNN achieves 80+% accuracy on ImageNet. The code will be available at Spikformer V2.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
Jan 10, 2023We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
Improving Auto-Augment via Augmentation-Wise Weight Sharing
Oct 22, 2020

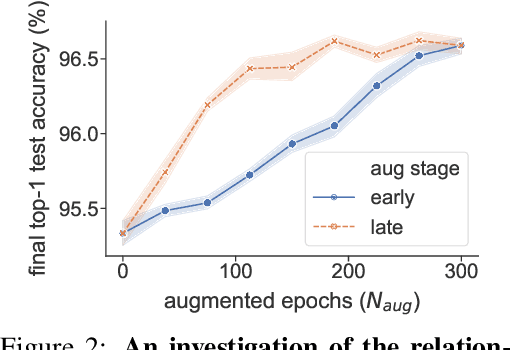
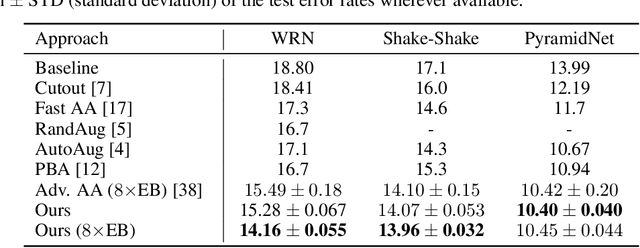
The recent progress on automatically searching augmentation policies has boosted the performance substantially for various tasks. A key component of automatic augmentation search is the evaluation process for a particular augmentation policy, which is utilized to return reward and usually runs thousands of times. A plain evaluation process, which includes full model training and validation, would be time-consuming. To achieve efficiency, many choose to sacrifice evaluation reliability for speed. In this paper, we dive into the dynamics of augmented training of the model. This inspires us to design a powerful and efficient proxy task based on the Augmentation-Wise Weight Sharing (AWS) to form a fast yet accurate evaluation process in an elegant way. Comprehensive analysis verifies the superiority of this approach in terms of effectiveness and efficiency. The augmentation policies found by our method achieve superior accuracies compared with existing auto-augmentation search methods. On CIFAR-10, we achieve a top-1 error rate of 1.24%, which is currently the best performing single model without extra training data. On ImageNet, we get a top-1 error rate of 20.36% for ResNet-50, which leads to 3.34% absolute error rate reduction over the baseline augmentation.
Powering One-shot Topological NAS with Stabilized Share-parameter Proxy
May 21, 2020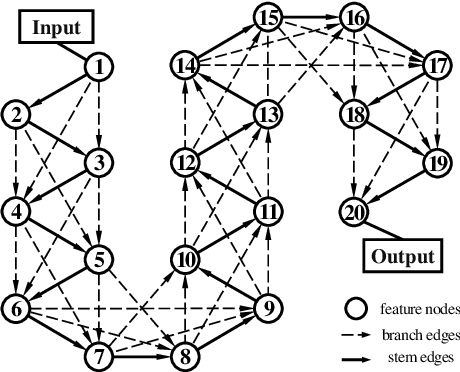

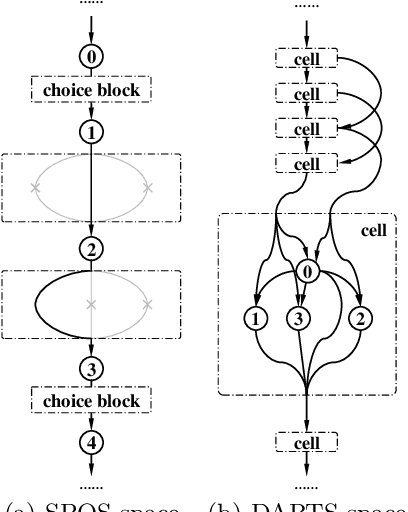
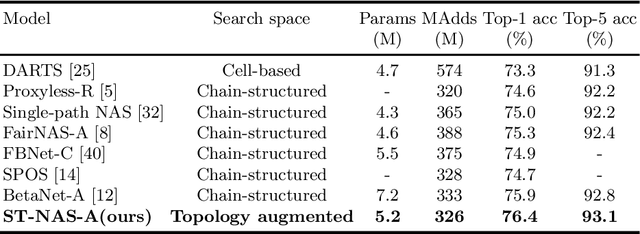
One-shot NAS method has attracted much interest from the research community due to its remarkable training efficiency and capacity to discover high performance models. However, the search spaces of previous one-shot based works usually relied on hand-craft design and were short for flexibility on the network topology. In this work, we try to enhance the one-shot NAS by exploring high-performing network architectures in our large-scale Topology Augmented Search Space (i.e., over 3.4*10^10 different topological structures). Specifically, the difficulties for architecture searching in such a complex space has been eliminated by the proposed stabilized share-parameter proxy, which employs Stochastic Gradient Langevin Dynamics to enable fast shared parameter sampling, so as to achieve stabilized measurement of architecture performance even in search space with complex topological structures. The proposed method, namely Stablized Topological Neural Architecture Search (ST-NAS), achieves state-of-the-art performance under Multiply-Adds (MAdds) constraint on ImageNet. Our lite model ST-NAS-A achieves 76.4% top-1 accuracy with only 326M MAdds. Our moderate model ST-NAS-B achieves 77.9% top-1 accuracy just required 503M MAdds. Both of our models offer superior performances in comparison to other concurrent works on one-shot NAS.