 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Online and Private Learnability under Distributional Constraints via Generalized Smoothness
Feb 24, 2026Understanding minimal assumptions that enable learning and generalization is perhaps the central question of learning theory. Several celebrated results in statistical learning theory, such as the VC theorem and Littlestone's characterization of online learnability, establish conditions on the hypothesis class that allow for learning under independent data and adversarial data, respectively. Building upon recent work bridging these extremes, we study sequential decision making under distributional adversaries that can adaptively choose data-generating distributions from a fixed family $U$ and ask when such problems are learnable with sample complexity that behaves like the favorable independent case. We provide a near complete characterization of families $U$ that admit learnability in terms of a notion known as generalized smoothness i.e. a distribution family admits VC-dimension-dependent regret bounds for every finite-VC hypothesis class if and only if it is generalized smooth. Further, we give universal algorithms that achieve low regret under any generalized smooth adversary without explicit knowledge of $U$. Finally, when $U$ is known, we provide refined bounds in terms of a combinatorial parameter, the fragmentation number, that captures how many disjoint regions can carry nontrivial mass under $U$. These results provide a nearly complete understanding of learnability under distributional adversaries. In addition, building upon the surprising connection between online learning and differential privacy, we show that the generalized smoothness also characterizes private learnability under distributional constraints.
Consistency and Inconsistency in $K$-Means Clustering
Jul 08, 2025A celebrated result of Pollard proves asymptotic consistency for $k$-means clustering when the population distribution has finite variance. In this work, we point out that the population-level $k$-means clustering problem is, in fact, well-posed under the weaker assumption of a finite expectation, and we investigate whether some form of asymptotic consistency holds in this setting. As we illustrate in a variety of negative results, the complete story is quite subtle; for example, the empirical $k$-means cluster centers may fail to converge even if there exists a unique set of population $k$-means cluster centers. A detailed analysis of our negative results reveals that inconsistency arises because of an extreme form of cluster imbalance, whereby the presence of outlying samples leads to some empirical $k$-means clusters possessing very few points. We then give a collection of positive results which show that some forms of asymptotic consistency, under only the assumption of finite expectation, may be recovered by imposing some a priori degree of balance among the empirical $k$-means clusters.
Collaborative Min-Max Regret in Grouped Multi-Armed Bandits
Jun 12, 2025We study the impact of sharing exploration in multi-armed bandits in a grouped setting where a set of groups have overlapping feasible action sets [Baek and Farias '24]. In this grouped bandit setting, groups share reward observations, and the objective is to minimize the collaborative regret, defined as the maximum regret across groups. This naturally captures applications in which one aims to balance the exploration burden between groups or populations -- it is known that standard algorithms can lead to significantly imbalanced exploration cost between groups. We address this problem by introducing an algorithm Col-UCB that dynamically coordinates exploration across groups. We show that Col-UCB achieves both optimal minimax and instance-dependent collaborative regret up to logarithmic factors. These bounds are adaptive to the structure of shared action sets between groups, providing insights into when collaboration yields significant benefits over each group learning their best action independently.
Distributionally-Constrained Adversaries in Online Learning
Jun 12, 2025There has been much recent interest in understanding the continuum from adversarial to stochastic settings in online learning, with various frameworks including smoothed settings proposed to bridge this gap. We consider the more general and flexible framework of distributionally constrained adversaries in which instances are drawn from distributions chosen by an adversary within some constrained distribution class [RST11]. Compared to smoothed analysis, we consider general distributional classes which allows for a fine-grained understanding of learning settings between fully stochastic and fully adversarial for which a learner can achieve non-trivial regret. We give a characterization for which distribution classes are learnable in this context against both oblivious and adaptive adversaries, providing insights into the types of interplay between the function class and distributional constraints on adversaries that enable learnability. In particular, our results recover and generalize learnability for known smoothed settings. Further, we show that for several natural function classes including linear classifiers, learning can be achieved without any prior knowledge of the distribution class -- in other words, a learner can simultaneously compete against any constrained adversary within learnable distribution classes.
Agnostic Smoothed Online Learning
Oct 07, 2024Classical results in statistical learning typically consider two extreme data-generating models: i.i.d. instances from an unknown distribution, or fully adversarial instances, often much more challenging statistically. To bridge the gap between these models, recent work introduced the smoothed framework, in which at each iteration an adversary generates instances from a distribution constrained to have density bounded by $\sigma^{-1}$ compared to some fixed base measure $\mu$. This framework interpolates between the i.i.d. and adversarial cases, depending on the value of $\sigma$. For the classical online prediction problem, most prior results in smoothed online learning rely on the arguably strong assumption that the base measure $\mu$ is known to the learner, contrasting with standard settings in the PAC learning or consistency literature. We consider the general agnostic problem in which the base measure is unknown and values are arbitrary. Along this direction, Block et al. showed that empirical risk minimization has sublinear regret under the well-specified assumption. We propose an algorithm R-Cover based on recursive coverings which is the first to guarantee sublinear regret for agnostic smoothed online learning without prior knowledge of $\mu$. For classification, we prove that R-Cover has adaptive regret $\tilde O(\sqrt{dT/\sigma})$ for function classes with VC dimension $d$, which is optimal up to logarithmic factors. For regression, we establish that R-Cover has sublinear oblivious regret for function classes with polynomial fat-shattering dimension growth.
Memory-Constrained Algorithms for Convex Optimization via Recursive Cutting-Planes
Jun 16, 2023We propose a family of recursive cutting-plane algorithms to solve feasibility problems with constrained memory, which can also be used for first-order convex optimization. Precisely, in order to find a point within a ball of radius $\epsilon$ with a separation oracle in dimension $d$ -- or to minimize $1$-Lipschitz convex functions to accuracy $\epsilon$ over the unit ball -- our algorithms use $\mathcal O(\frac{d^2}{p}\ln \frac{1}{\epsilon})$ bits of memory, and make $\mathcal O((C\frac{d}{p}\ln \frac{1}{\epsilon})^p)$ oracle calls, for some universal constant $C \geq 1$. The family is parametrized by $p\in[d]$ and provides an oracle-complexity/memory trade-off in the sub-polynomial regime $\ln\frac{1}{\epsilon}\gg\ln d$. While several works gave lower-bound trade-offs (impossibility results) -- we explicit here their dependence with $\ln\frac{1}{\epsilon}$, showing that these also hold in any sub-polynomial regime -- to the best of our knowledge this is the first class of algorithms that provides a positive trade-off between gradient descent and cutting-plane methods in any regime with $\epsilon\leq 1/\sqrt d$. The algorithms divide the $d$ variables into $p$ blocks and optimize over blocks sequentially, with approximate separation vectors constructed using a variant of Vaidya's method. In the regime $\epsilon \leq d^{-\Omega(d)}$, our algorithm with $p=d$ achieves the information-theoretic optimal memory usage and improves the oracle-complexity of gradient descent.
Quadratic Memory is Necessary for Optimal Query Complexity in Convex Optimization: Center-of-Mass is Pareto-Optimal
Feb 09, 2023
We give query complexity lower bounds for convex optimization and the related feasibility problem. We show that quadratic memory is necessary to achieve the optimal oracle complexity for first-order convex optimization. In particular, this shows that center-of-mass cutting-planes algorithms in dimension $d$ which use $\tilde O(d^2)$ memory and $\tilde O(d)$ queries are Pareto-optimal for both convex optimization and the feasibility problem, up to logarithmic factors. Precisely, we prove that to minimize $1$-Lipschitz convex functions over the unit ball to $1/d^4$ accuracy, any deterministic first-order algorithms using at most $d^{2-\delta}$ bits of memory must make $\tilde\Omega(d^{1+\delta/3})$ queries, for any $\delta\in[0,1]$. For the feasibility problem, in which an algorithm only has access to a separation oracle, we show a stronger trade-off: for at most $d^{2-\delta}$ memory, the number of queries required is $\tilde\Omega(d^{1+\delta})$. This resolves a COLT 2019 open problem of Woodworth and Srebro.
Universal Regression with Adversarial Responses
Mar 14, 2022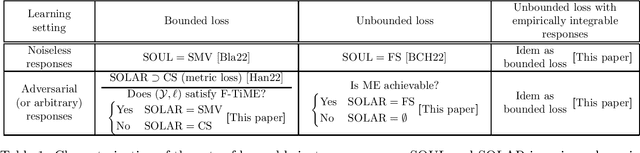
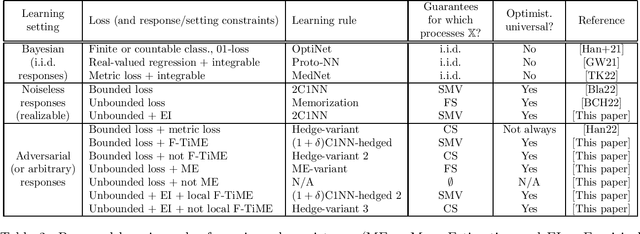
We provide algorithms for regression with adversarial responses under large classes of non-i.i.d. instance sequences, on general separable metric spaces, with provably minimal assumptions. We also give characterizations of learnability in this regression context. We consider universal consistency which asks for strong consistency of a learner without restrictions on the value responses. Our analysis shows that such objective is achievable for a significantly larger class of instance sequences than stationary processes, and unveils a fundamental dichotomy between value spaces: whether finite-horizon mean-estimation is achievable or not. We further provide optimistically universal learning rules, i.e., such that if they fail to achieve universal consistency, any other algorithm will fail as well. For unbounded losses, we propose a mild integrability condition under which there exist algorithms for adversarial regression under large classes of non-i.i.d. instance sequences. In addition, our analysis also provides a learning rule for mean-estimation in general metric spaces that is consistent under adversarial responses without any moment conditions on the sequence, a result of independent interest.
Universal Online Learning: an Optimistically Universal Learning Rule
Jan 16, 2022We study the subject of universal online learning with non-i.i.d. processes for bounded losses. The notion of an universally consistent learning was defined by Hanneke in an effort to study learning theory under minimal assumptions, where the objective is to obtain low long-run average loss for any target function. We are interested in characterizing processes for which learning is possible and whether there exist learning rules guaranteed to be universally consistent given the only assumption that such learning is possible. The case of unbounded losses is very restrictive, since the learnable processes almost surely visit a finite number of points and as a result, simple memorization is optimistically universal. We focus on the bounded setting and give a complete characterization of the processes admitting strong and weak universal learning. We further show that k-nearest neighbor algorithm (kNN) is not optimistically universal and present a novel variant of 1NN which is optimistically universal for general input and value spaces in both strong and weak setting. This closes all COLT 2021 open problems posed by Hanneke on universal online learning.
Universal Online Learning with Bounded Loss: Reduction to Binary Classification
Dec 29, 2021We study universal consistency of non-i.i.d. processes in the context of online learning. A stochastic process is said to admit universal consistency if there exists a learner that achieves vanishing average loss for any measurable response function on this process. When the loss function is unbounded, Blanchard et al. showed that the only processes admitting strong universal consistency are those taking a finite number of values almost surely. However, when the loss function is bounded, the class of processes admitting strong universal consistency is much richer and its characterization could be dependent on the response setting (Hanneke). In this paper, we show that this class of processes is independent from the response setting thereby closing an open question (Hanneke, Open Problem 3). Specifically, we show that the class of processes that admit universal online learning is the same for binary classification as for multiclass classification with countable number of classes. Consequently, any output setting with bounded loss can be reduced to binary classification. Our reduction is constructive and practical. Indeed, we show that the nearest neighbor algorithm is transported by our construction. For binary classification on a process admitting strong universal learning, we prove that nearest neighbor successfully learns at least all finite unions of intervals.