 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Speech-to-speech Translation without Textual Annotation using Bottleneck Features
Paper and Code
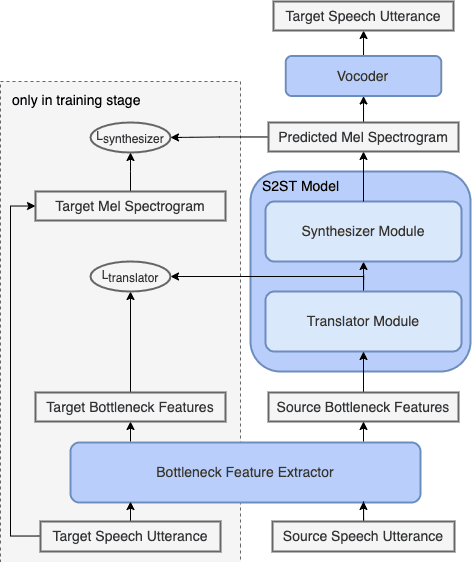

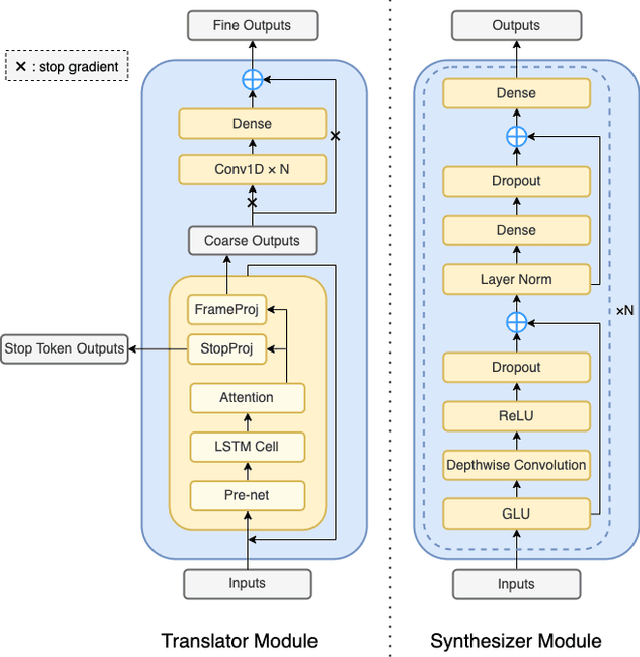
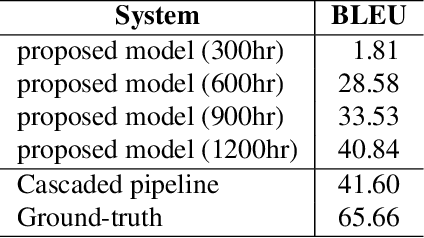
Speech-to-speech translation directly translates a speech utterance to another between different languages, and has great potential in tasks such as simultaneous interpretation. State-of-art models usually contains an auxiliary module for phoneme sequences prediction, and this requires textual annotation of the training dataset. We propose a direct speech-to-speech translation model which can be trained without any textual annotation or content information. Instead of introducing an auxiliary phoneme prediction task in the model, we propose to use bottleneck features as intermediate training objectives for our model to ensure the translation performance of the system. Experiments on Mandarin-Cantonese speech translation demonstrate the feasibility of the proposed approach and the performance can match a cascaded system with respect of translation and synthesis qualities.