 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
AdaST: Dynamically Adapting Encoder States in the Decoder for End-to-End Speech-to-Text Translation
Mar 18, 2025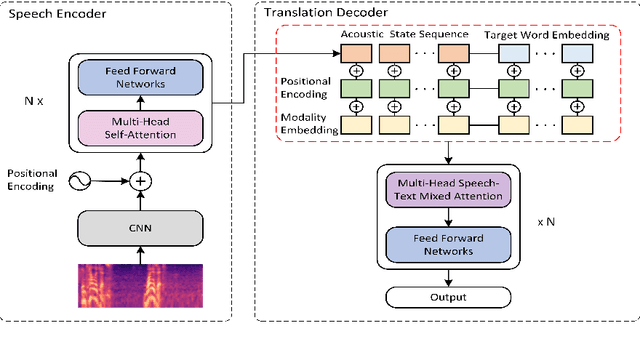

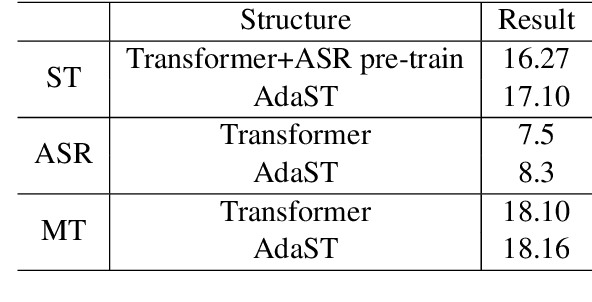

In end-to-end speech translation, acoustic representations learned by the encoder are usually fixed and static, from the perspective of the decoder, which is not desirable for dealing with the cross-modal and cross-lingual challenge in speech translation. In this paper, we show the benefits of varying acoustic states according to decoder hidden states and propose an adaptive speech-to-text translation model that is able to dynamically adapt acoustic states in the decoder. We concatenate the acoustic state and target word embedding sequence and feed the concatenated sequence into subsequent blocks in the decoder. In order to model the deep interaction between acoustic states and target hidden states, a speech-text mixed attention sublayer is introduced to replace the conventional cross-attention network. Experiment results on two widely-used datasets show that the proposed method significantly outperforms state-of-the-art neural speech translation models.
Joint Training And Decoding for Multilingual End-to-End Simultaneous Speech Translation
Mar 14, 2025Recent studies on end-to-end speech translation(ST) have facilitated the exploration of multilingual end-to-end ST and end-to-end simultaneous ST. In this paper, we investigate end-to-end simultaneous speech translation in a one-to-many multilingual setting which is closer to applications in real scenarios. We explore a separate decoder architecture and a unified architecture for joint synchronous training in this scenario. To further explore knowledge transfer across languages, we propose an asynchronous training strategy on the proposed unified decoder architecture. A multi-way aligned multilingual end-to-end ST dataset was curated as a benchmark testbed to evaluate our methods. Experimental results demonstrate the effectiveness of our models on the collected dataset. Our codes and data are available at: https://github.com/XiaoMi/TED-MMST.
A Comprehensive Evaluation of Quantization Strategies for Large Language Models
Feb 26, 2024



Increasing the number of parameters in large language models (LLMs) usually improves performance in downstream tasks but raises compute and memory costs, making deployment difficult in resource-limited settings. Quantization techniques, which reduce the bits needed for model weights or activations with minimal performance loss, have become popular due to the rise of LLMs. However, most quantization studies use pre-trained LLMs, and the impact of quantization on instruction-tuned LLMs and the relationship between perplexity and benchmark performance of quantized LLMs are not well understood. Evaluation of quantized LLMs is often limited to language modeling and a few classification tasks, leaving their performance on other benchmarks unclear. To address these gaps, we propose a structured evaluation framework consisting of three critical dimensions: (1) knowledge \& capacity, (2) alignment, and (3) efficiency, and conduct extensive experiments across ten diverse benchmarks. Our experimental results indicate that LLMs with 4-bit quantization can retain performance comparable to their non-quantized counterparts, and perplexity can serve as a proxy metric for quantized LLMs on most benchmarks. Furthermore, quantized LLMs with larger parameter scales can outperform smaller LLMs. Despite the memory savings achieved through quantization, it can also slow down the inference speed of LLMs. Consequently, substantial engineering efforts and hardware support are imperative to achieve a balanced optimization of decoding speed and memory consumption in the context of quantized LLMs.