 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaST: Dynamically Adapting Encoder States in the Decoder for End-to-End Speech-to-Text Translation
Paper and Code
Mar 18, 2025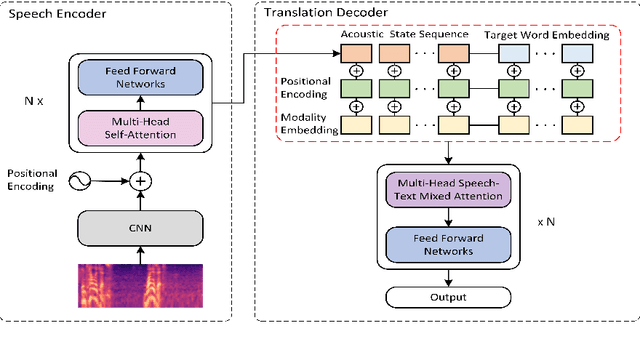

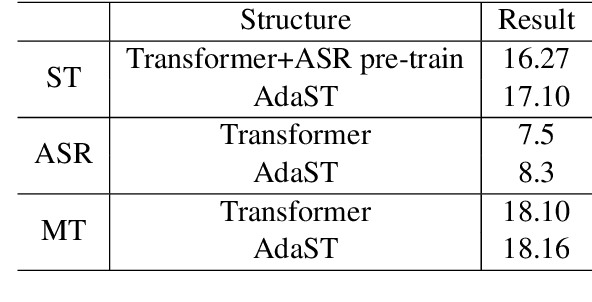

In end-to-end speech translation, acoustic representations learned by the encoder are usually fixed and static, from the perspective of the decoder, which is not desirable for dealing with the cross-modal and cross-lingual challenge in speech translation. In this paper, we show the benefits of varying acoustic states according to decoder hidden states and propose an adaptive speech-to-text translation model that is able to dynamically adapt acoustic states in the decoder. We concatenate the acoustic state and target word embedding sequence and feed the concatenated sequence into subsequent blocks in the decoder. In order to model the deep interaction between acoustic states and target hidden states, a speech-text mixed attention sublayer is introduced to replace the conventional cross-attention network. Experiment results on two widely-used datasets show that the proposed method significantly outperforms state-of-the-art neural speech translation models.