 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning of Lexical Semantic Families for Argumentative Discourse Units Identification
Sep 06, 2022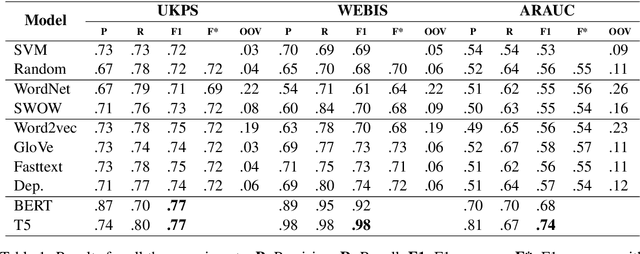



Argument mining tasks require an informed range of low to high complexity linguistic phenomena and commonsense knowledge. Previous work has shown that pre-trained language models are highly effective at encoding syntactic and semantic linguistic phenomena when applied with transfer learning techniques and built on different pre-training objectives. It remains an issue of how much the existing pre-trained language models encompass the complexity of argument mining tasks. We rely on experimentation to shed light on how language models obtained from different lexical semantic families leverage the performance of the identification of argumentative discourse units task. Experimental results show that transfer learning techniques are beneficial to the task and that current methods may be insufficient to leverage commonsense knowledge from different lexical semantic families.
Comparative Probing of Lexical Semantics Theories for Cognitive Plausibility and Technological Usefulness
Nov 16, 2020
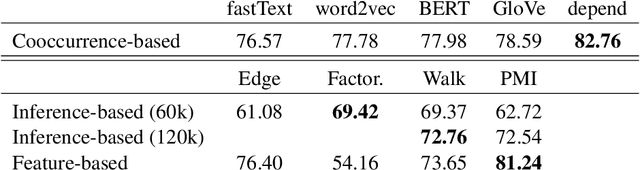

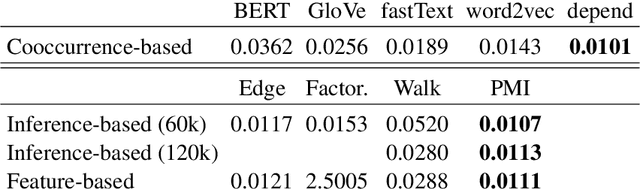
Lexical semantics theories differ in advocating that the meaning of words is represented as an inference graph, a feature mapping or a vector space, thus raising the question: is it the case that one of these approaches is superior to the others in representing lexical semantics appropriately? Or in its non antagonistic counterpart: could there be a unified account of lexical semantics where these approaches seamlessly emerge as (partial) renderings of (different) aspects of a core semantic knowledge base? In this paper, we contribute to these research questions with a number of experiments that systematically probe different lexical semantics theories for their levels of cognitive plausibility and of technological usefulness. The empirical findings obtained from these experiments advance our insight on lexical semantics as the feature-based approach emerges as superior to the other ones, and arguably also move us closer to finding answers to the research questions above.