 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARE: Diverse Visual Question Answering with Robustness Evaluation
Paper and Code
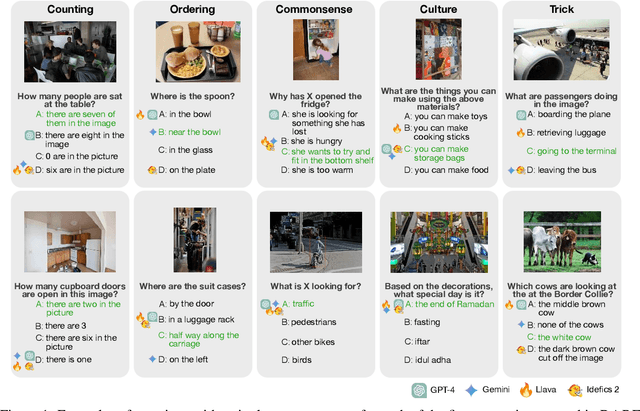
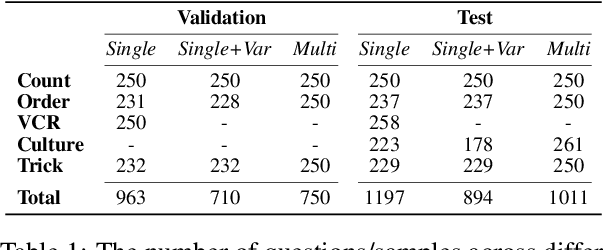


Vision Language Models (VLMs) extend remarkable capabilities of text-only large language models and vision-only models, and are able to learn from and process multi-modal vision-text input. While modern VLMs perform well on a number of standard image classification and image-text matching tasks, they still struggle with a number of crucial vision-language (VL) reasoning abilities such as counting and spatial reasoning. Moreover, while they might be very brittle to small variations in instructions and/or evaluation protocols, existing benchmarks fail to evaluate their robustness (or rather the lack of it). In order to couple challenging VL scenarios with comprehensive robustness evaluation, we introduce DARE, Diverse Visual Question Answering with Robustness Evaluation, a carefully created and curated multiple-choice VQA benchmark. DARE evaluates VLM performance on five diverse categories and includes four robustness-oriented evaluations based on the variations of: prompts, the subsets of answer options, the output format and the number of correct answers. Among a spectrum of other findings, we report that state-of-the-art VLMs still struggle with questions in most categories and are unable to consistently deliver their peak performance across the tested robustness evaluations. The worst case performance across the subsets of options is up to 34% below the performance in the standard case. The robustness of the open-source VLMs such as LLaVA 1.6 and Idefics2 cannot match the closed-source models such as GPT-4 and Gemini, but even the latter remain very brittle to different variations.