 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Pretraining for Pixel Language Models
May 27, 2025Pixel language models operate directly on images of rendered text, eliminating the need for a fixed vocabulary. While these models have demonstrated strong capabilities for downstream cross-lingual transfer, multilingual pretraining remains underexplored. We introduce PIXEL-M4, a model pretrained on four visually and linguistically diverse languages: English, Hindi, Ukrainian, and Simplified Chinese. Multilingual evaluations on semantic and syntactic tasks show that PIXEL-M4 outperforms an English-only counterpart on non-Latin scripts. Word-level probing analyses confirm that PIXEL-M4 captures rich linguistic features, even in languages not seen during pretraining. Furthermore, an analysis of its hidden representations shows that multilingual pretraining yields a semantic embedding space closely aligned across the languages used for pretraining. This work demonstrates that multilingual pretraining substantially enhances the capability of pixel language models to effectively support a diverse set of languages.
Overcoming Vocabulary Constraints with Pixel-level Fallback
Apr 02, 2025



Subword tokenization requires balancing computational efficiency and vocabulary coverage, which often leads to suboptimal performance on languages and scripts not prioritized during training. We propose to augment pretrained language models with a vocabulary-free encoder that generates input embeddings from text rendered as pixels. Through experiments on English-centric language models, we demonstrate that our approach substantially improves machine translation performance and facilitates effective cross-lingual transfer, outperforming tokenizer-based methods. Furthermore, we find that pixel-based representations outperform byte-level approaches and standard vocabulary expansion. Our approach enhances the multilingual capabilities of monolingual language models without extensive retraining and reduces decoding latency via input compression.
Text Rendering Strategies for Pixel Language Models
Nov 01, 2023



Pixel-based language models process text rendered as images, which allows them to handle any script, making them a promising approach to open vocabulary language modelling. However, recent approaches use text renderers that produce a large set of almost-equivalent input patches, which may prove sub-optimal for downstream tasks, due to redundancy in the input representations. In this paper, we investigate four approaches to rendering text in the PIXEL model (Rust et al., 2023), and find that simple character bigram rendering brings improved performance on sentence-level tasks without compromising performance on token-level or multilingual tasks. This new rendering strategy also makes it possible to train a more compact model with only 22M parameters that performs on par with the original 86M parameter model. Our analyses show that character bigram rendering leads to a consistently better model but with an anisotropic patch embedding space, driven by a patch frequency bias, highlighting the connections between image patch- and tokenization-based language models.
Data Curation for Image Captioning with Text-to-Image Generative Models
May 05, 2023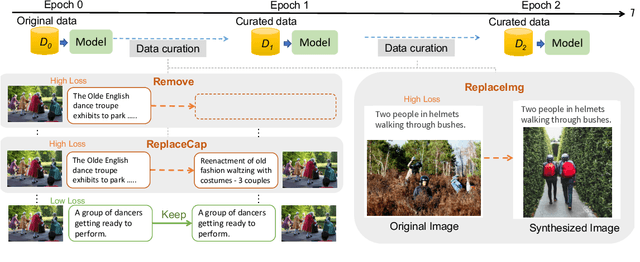
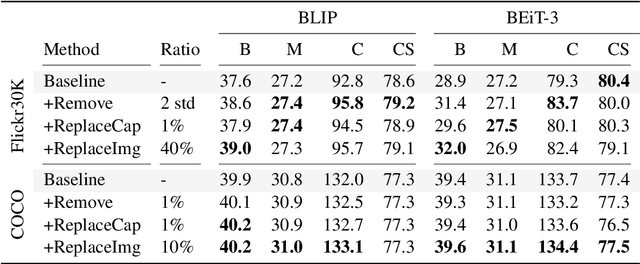

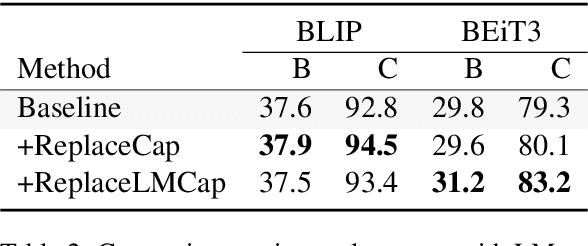
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.
Language Modelling with Pixels
Jul 14, 2022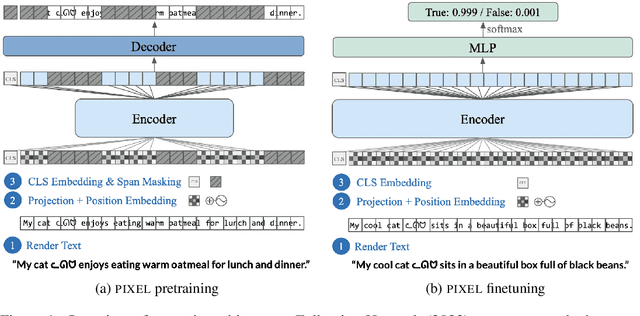
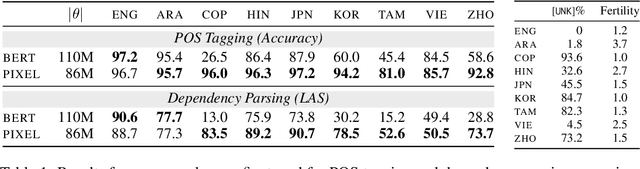


Language models are defined over a finite set of inputs, which creates a vocabulary bottleneck when we attempt to scale the number of supported languages. Tackling this bottleneck results in a trade-off between what can be represented in the embedding matrix and computational issues in the output layer. This paper introduces PIXEL, the Pixel-based Encoder of Language, which suffers from neither of these issues. PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained to reconstruct the pixels of masked patches, instead of predicting a distribution over tokens. We pretrain the 86M parameter PIXEL model on the same English data as BERT and evaluate on syntactic and semantic tasks in typologically diverse languages, including various non-Latin scripts. We find that PIXEL substantially outperforms BERT on syntactic and semantic processing tasks on scripts that are not found in the pretraining data, but PIXEL is slightly weaker than BERT when working with Latin scripts. Furthermore, we find that PIXEL is more robust to noisy text inputs than BERT, further confirming the benefits of modelling language with pixels.