 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Curation for Image Captioning with Text-to-Image Generative Models
Paper and Code
May 05, 2023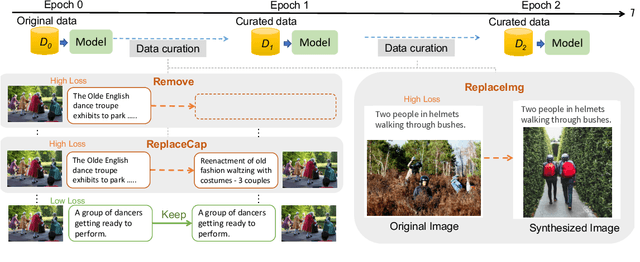
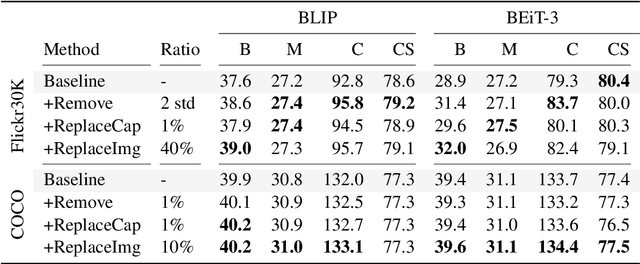

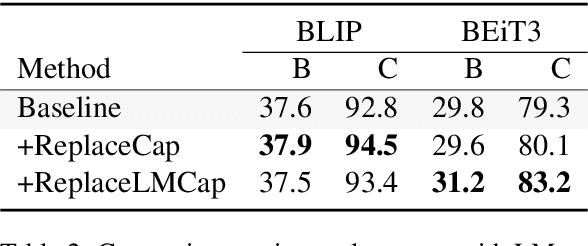
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.