Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Zero Resource Speech Challenge 2017
Paper and Code
Dec 12, 2017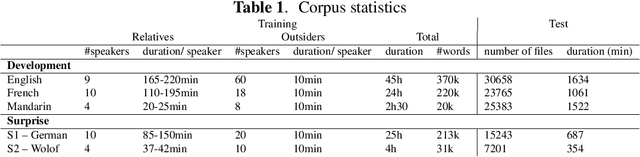
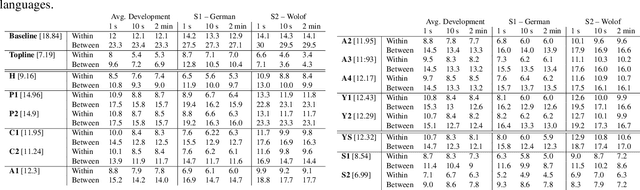
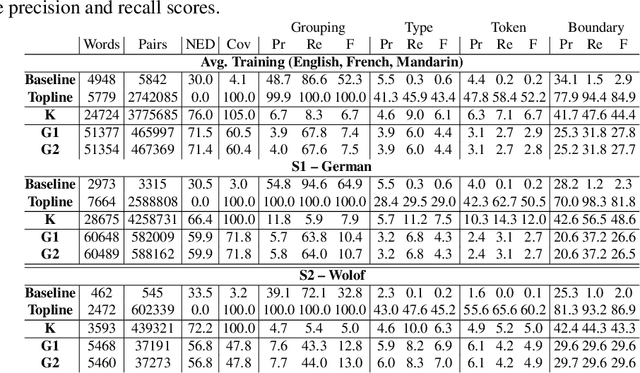
We describe a new challenge aimed at discovering subword and word units from raw speech. This challenge is the followup to the Zero Resource Speech Challenge 2015. It aims at constructing systems that generalize across languages and adapt to new speakers. The design features and evaluation metrics of the challenge are presented and the results of seventeen models are discussed.
* IEEE ASRU (Automatic Speech Recognition and Understanding) 2017.
Okinawa, Japan
View paper on