 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021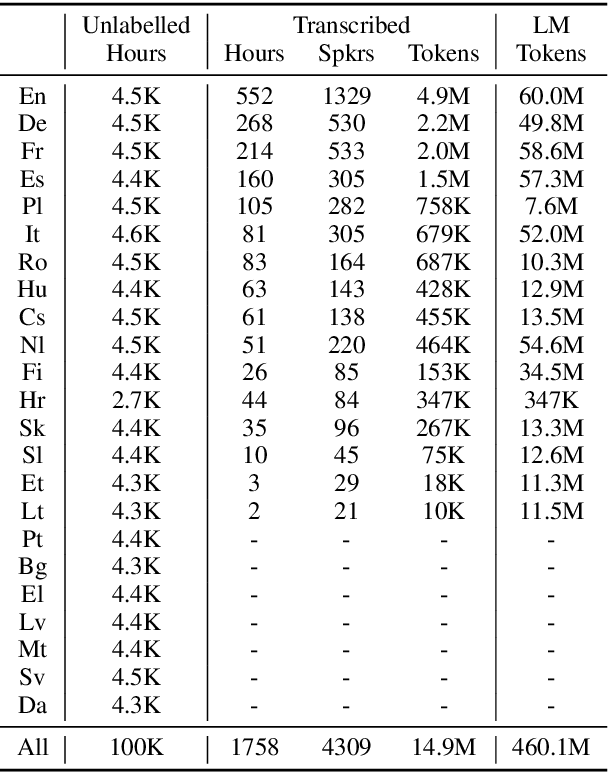
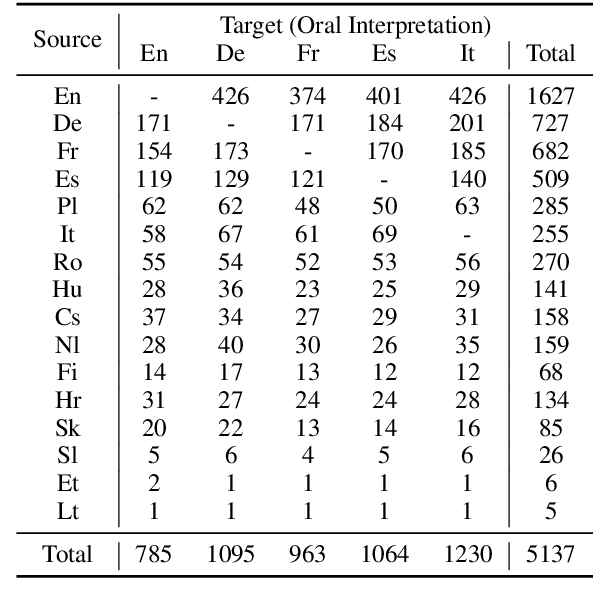

We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
Joint Masked CPC and CTC Training for ASR
Oct 30, 2020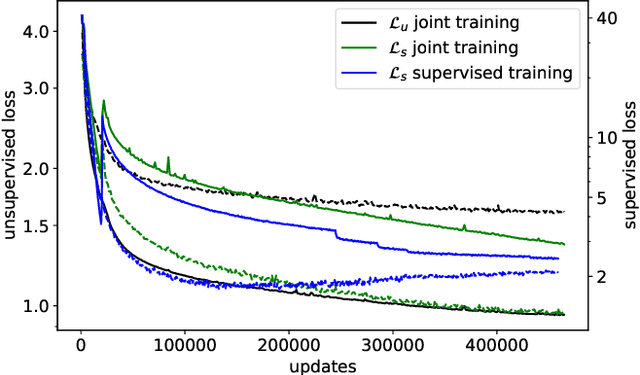
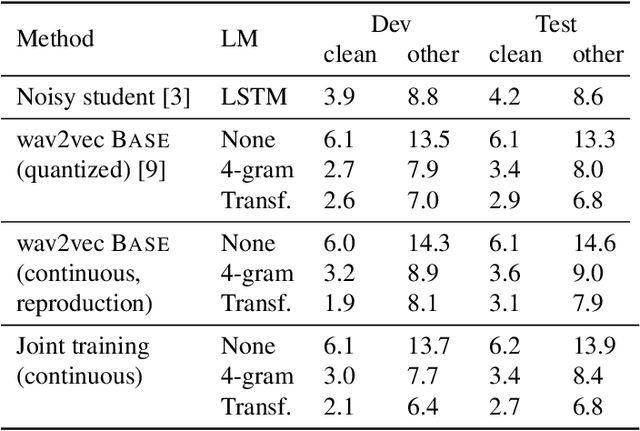
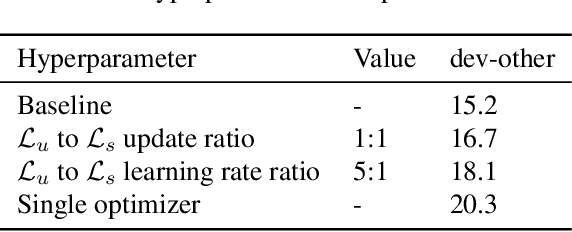
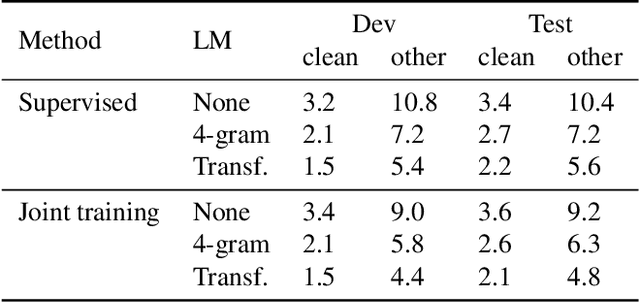
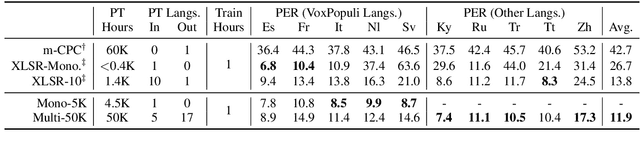
Self-supervised learning (SSL) has shown promise in learning representations of audio that are useful for automatic speech recognition (ASR). But, training SSL models like wav2vec~2.0 requires a two-stage pipeline. In this paper we demonstrate a single-stage training of ASR models that can utilize both unlabeled and labeled data. During training, we alternately minimize two losses: an unsupervised masked Contrastive Predictive Coding (CPC) loss and the supervised audio-to-text alignment loss Connectionist Temporal Classification (CTC). We show that this joint training method directly optimizes performance for the downstream ASR task using unsupervised data while achieving similar word error rates to wav2vec~2.0 on the Librispeech 100-hour dataset. Finally, we postulate that solving the contrastive task is a regularization for the supervised CTC loss.
Linear Range in Gradient Descent
May 23, 2019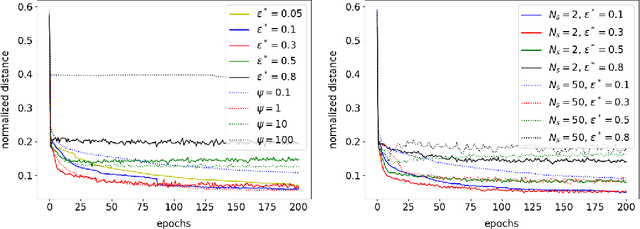
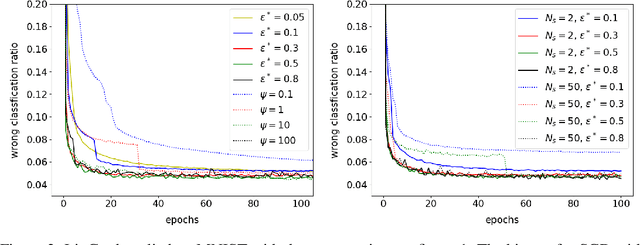
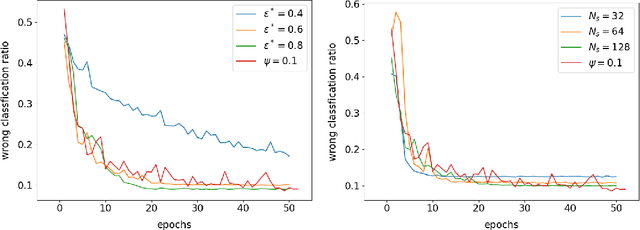
This paper defines linear range as the range of parameter perturbations which lead to approximately linear perturbations in the states of a network. We compute linear range from the difference between actual perturbations in states and the tangent solution. Linear range is a new criterion for estimating the effectivenss of gradients and thus having many possible applications. In particular, we propose that the optimal learning rate at the initial stages of training is such that parameter changes on all minibatches are within linear range. We demonstrate our algorithm on two shallow neural networks and a ResNet.