Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Range in Gradient Descent
Paper and Code
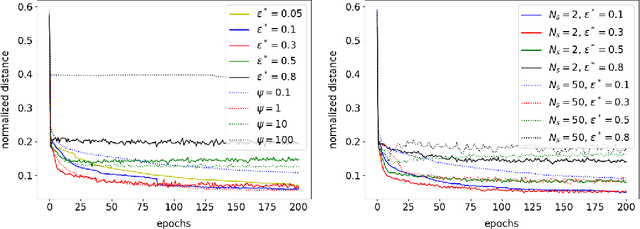
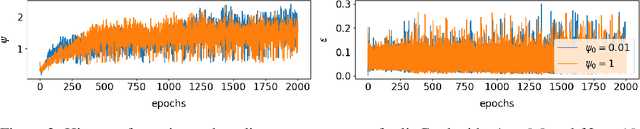
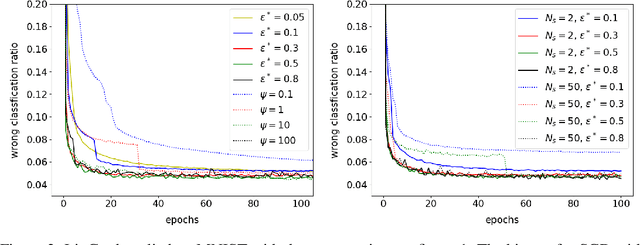
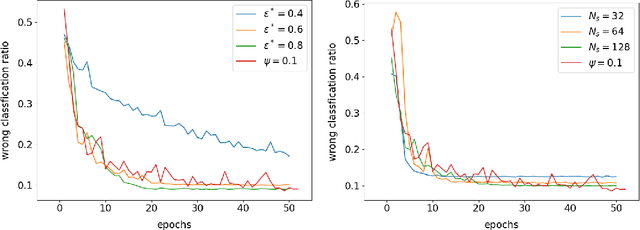
This paper defines linear range as the range of parameter perturbations which lead to approximately linear perturbations in the states of a network. We compute linear range from the difference between actual perturbations in states and the tangent solution. Linear range is a new criterion for estimating the effectivenss of gradients and thus having many possible applications. In particular, we propose that the optimal learning rate at the initial stages of training is such that parameter changes on all minibatches are within linear range. We demonstrate our algorithm on two shallow neural networks and a ResNet.
* 9 pages, 4 figures
View paper on