Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Dimensionality of Word Embeddings
Paper and Code
Apr 13, 2017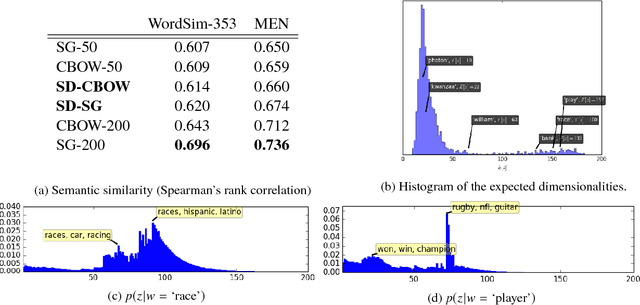
We describe a method for learning word embeddings with data-dependent dimensionality. Our Stochastic Dimensionality Skip-Gram (SD-SG) and Stochastic Dimensionality Continuous Bag-of-Words (SD-CBOW) are nonparametric analogs of Mikolov et al.'s (2013) well-known 'word2vec' models. Vector dimensionality is made dynamic by employing techniques used by Cote & Larochelle (2016) to define an RBM with an infinite number of hidden units. We show qualitatively and quantitatively that SD-SG and SD-CBOW are competitive with their fixed-dimension counterparts while providing a distribution over embedding dimensionalities, which offers a window into how semantics distribute across dimensions.
View paper on