 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Spectral Bias of Shallow Neural Network Learning is Shaped by the Choice of Non-linearity
Mar 13, 2025



Despite classical statistical theory predicting severe overfitting, modern massively overparameterized neural networks still generalize well. This unexpected property is attributed to the network's so-called implicit bias, which describes its propensity to converge to solutions that generalize effectively, among the many possible that correctly label the training data. The aim of our research is to explore this bias from a new perspective, focusing on how non-linear activation functions contribute to shaping it. First, we introduce a reparameterization which removes a continuous weight rescaling symmetry. Second, in the kernel regime, we leverage this reparameterization to generalize recent findings that relate shallow Neural Networks to the Radon transform, deriving an explicit formula for the implicit bias induced by a broad class of activation functions. Specifically, by utilizing the connection between the Radon transform and the Fourier transform, we interpret the kernel regime's inductive bias as minimizing a spectral seminorm that penalizes high-frequency components, in a manner dependent on the activation function. Finally, in the adaptive regime, we demonstrate the existence of local dynamical attractors that facilitate the formation of clusters of hyperplanes where the input to a neuron's activation function is zero, yielding alignment between many neurons' response functions. We confirm these theoretical results with simulations. All together, our work provides a deeper understanding of the mechanisms underlying the generalization capabilities of overparameterized neural networks and its relation with the implicit bias, offering potential pathways for designing more efficient and robust models.
A Quantitative Approach to Predicting Representational Learning and Performance in Neural Networks
Jul 14, 2023



A key property of neural networks (both biological and artificial) is how they learn to represent and manipulate input information in order to solve a task. Different types of representations may be suited to different types of tasks, making identifying and understanding learned representations a critical part of understanding and designing useful networks. In this paper, we introduce a new pseudo-kernel based tool for analyzing and predicting learned representations, based only on the initial conditions of the network and the training curriculum. We validate the method on a simple test case, before demonstrating its use on a question about the effects of representational learning on sequential single versus concurrent multitask performance. We show that our method can be used to predict the effects of the scale of weight initialization and training curriculum on representational learning and downstream concurrent multitasking performance.
Shallow Univariate ReLu Networks as Splines: Initialization, Loss Surface, Hessian, & Gradient Flow Dynamics
Aug 04, 2020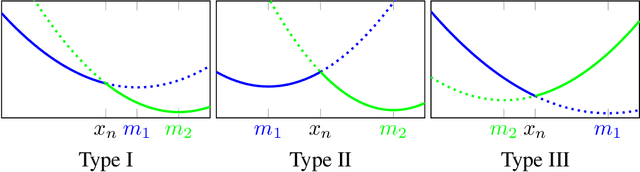
Understanding the learning dynamics and inductive bias of neural networks (NNs) is hindered by the opacity of the relationship between NN parameters and the function represented. We propose reparametrizing ReLU NNs as continuous piecewise linear splines. Using this spline lens, we study learning dynamics in shallow univariate ReLU NNs, finding unexpected insights and explanations for several perplexing phenomena. We develop a surprisingly simple and transparent view of the structure of the loss surface, including its critical and fixed points, Hessian, and Hessian spectrum. We also show that standard weight initializations yield very flat functions, and that this flatness, together with overparametrization and the initial weight scale, is responsible for the strength and type of implicit regularization, consistent with recent work arXiv:1906.05827. Our implicit regularization results are complementary to recent work arXiv:1906.07842, done independently, which showed that initialization scale critically controls implicit regularization via a kernel-based argument. Our spline-based approach reproduces their key implicit regularization results but in a far more intuitive and transparent manner. Going forward, our spline-based approach is likely to extend naturally to the multivariate and deep settings, and will play a foundational role in efforts to understand neural networks. Videos of learning dynamics using a spline-based visualization are available at http://shorturl.at/tFWZ2.
Using Learning Dynamics to Explore the Role of Implicit Regularization in Adversarial Examples
Jun 19, 2020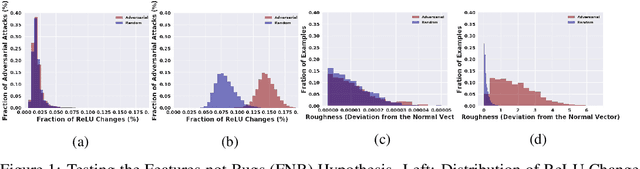
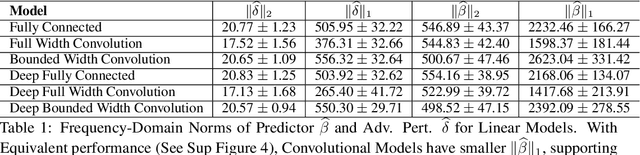
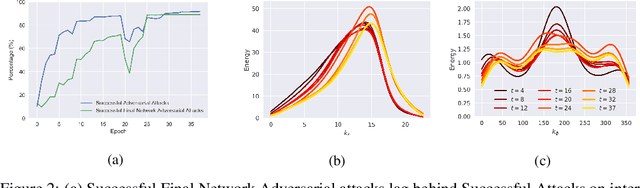
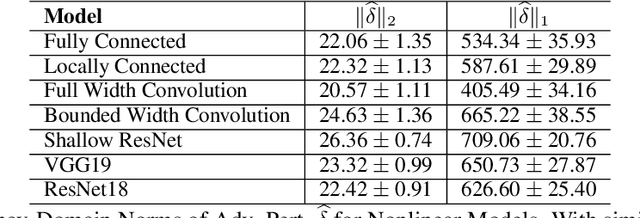
Recent work (Ilyas et al, 2019) suggests that adversarial examples are features not bugs. If adversarial perturbations are indeed useful but non-robust features, then what is their origin? In order to answer these questions, we systematically examine the learning dynamics of adversarial perturbations both in the pixel and frequency domains. We find that: (1) adversarial examples are not present at initialization but instead emerge very early in training, typically within the first epochs, as verified by a novel breakpoint-based analysis; (2) the low-amplitude high-frequency nature of common adversarial perturbations in natural images is critically dependent on an implicit bias towards sparsity in the frequency domain; and (3) the origin of this bias is the locality and translation invariance of convolutional filters, along with (4) the existence of useful frequency-domain features in natural images. We provide a simple theoretical explanation for these observations, providing a clear and minimalist target for theorists in future work. Looking forward, our findings suggest that analyzing the learning dynamics of perturbations can provide useful insights for understanding the origin of adversarial sensitivities and developing robust solutions.
A model of reward-modulated motor learning with parallelcortical and basal ganglia pathways
Mar 08, 2018



Many recent studies of the motor system are divided into two distinct approaches: Those that investigate how motor responses are encoded in cortical neurons' firing rate dynamics and those that study the learning rules by which mammals and songbirds develop reliable motor responses. Computationally, the first approach is encapsulated by reservoir computing models, which can learn intricate motor tasks and produce internal dynamics strikingly similar to those of motor cortical neurons, but rely on biologically unrealistic learning rules. The more realistic learning rules developed by the second approach are often derived for simplified, discrete tasks in contrast to the intricate dynamics that characterize real motor responses. We bridge these two approaches to develop a biologically realistic learning rule for reservoir computing. Our algorithm learns simulated motor tasks on which previous reservoir computing algorithms fail, and reproduces experimental findings including those that relate motor learning to Parkinson's disease and its treatment.