 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Univariate ReLu Networks as Splines: Initialization, Loss Surface, Hessian, & Gradient Flow Dynamics
Paper and Code
Aug 04, 2020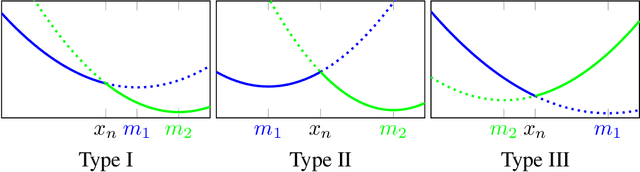
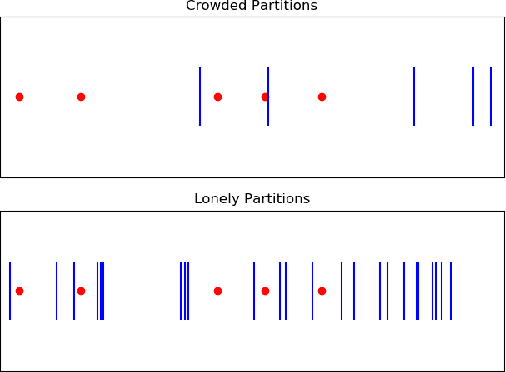
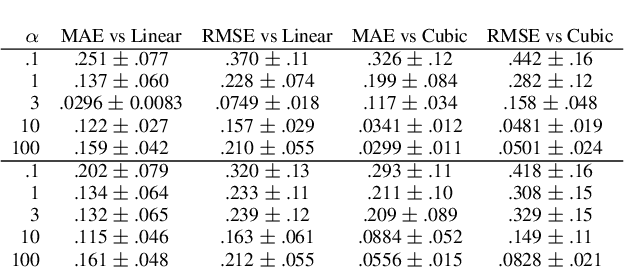
Understanding the learning dynamics and inductive bias of neural networks (NNs) is hindered by the opacity of the relationship between NN parameters and the function represented. We propose reparametrizing ReLU NNs as continuous piecewise linear splines. Using this spline lens, we study learning dynamics in shallow univariate ReLU NNs, finding unexpected insights and explanations for several perplexing phenomena. We develop a surprisingly simple and transparent view of the structure of the loss surface, including its critical and fixed points, Hessian, and Hessian spectrum. We also show that standard weight initializations yield very flat functions, and that this flatness, together with overparametrization and the initial weight scale, is responsible for the strength and type of implicit regularization, consistent with recent work arXiv:1906.05827. Our implicit regularization results are complementary to recent work arXiv:1906.07842, done independently, which showed that initialization scale critically controls implicit regularization via a kernel-based argument. Our spline-based approach reproduces their key implicit regularization results but in a far more intuitive and transparent manner. Going forward, our spline-based approach is likely to extend naturally to the multivariate and deep settings, and will play a foundational role in efforts to understand neural networks. Videos of learning dynamics using a spline-based visualization are available at http://shorturl.at/tFWZ2.