 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
Paper and Code
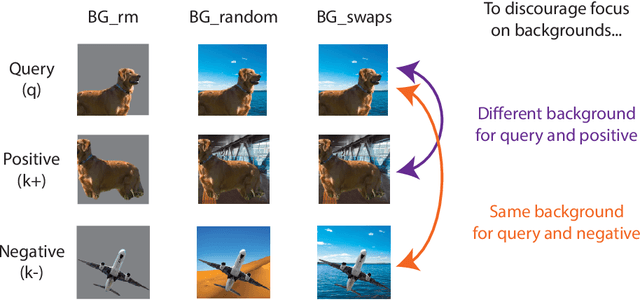
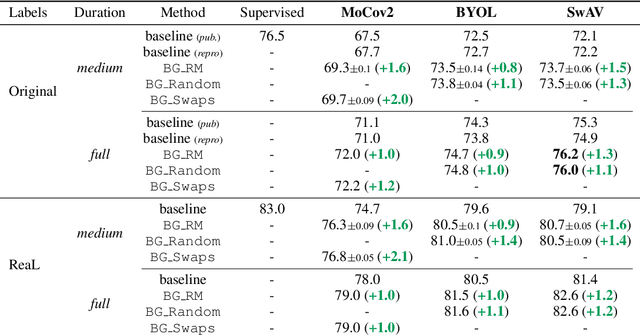
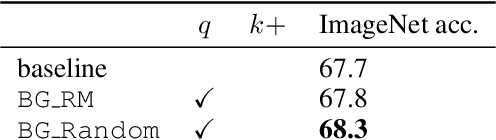
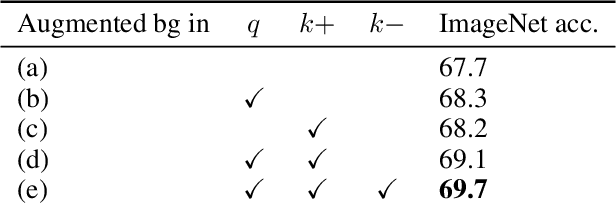
Unsupervised representation learning is an important challenge in computer vision, with self-supervised learning methods recently closing the gap to supervised representation learning. An important ingredient in high-performing self-supervised methods is the use of data augmentation by training models to place different augmented views of the same image nearby in embedding space. However, commonly used augmentation pipelines treat images holistically, disregarding the semantic relevance of parts of an image-e.g. a subject vs. a background-which can lead to the learning of spurious correlations. Our work addresses this problem by investigating a class of simple, yet highly effective "background augmentations", which encourage models to focus on semantically-relevant content by discouraging them from focusing on image backgrounds. Background augmentations lead to substantial improvements (+1-2% on ImageNet-1k) in performance across a spectrum of state-of-the art self-supervised methods (MoCov2, BYOL, SwAV) on a variety of tasks, allowing us to reach within 0.3% of supervised performance. We also demonstrate that background augmentations improve robustness to a number of out of distribution settings, including natural adversarial examples, the backgrounds challenge, adversarial attacks, and ReaL ImageNet.