 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
Mar 23, 2021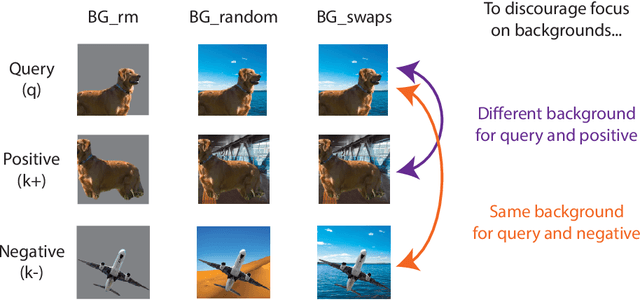
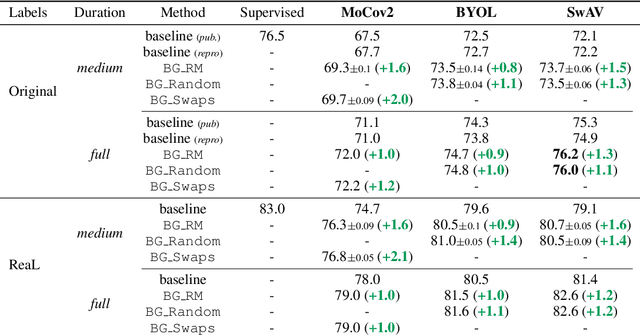
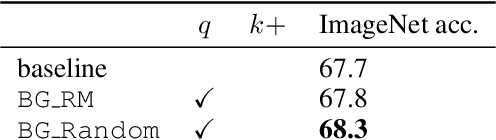
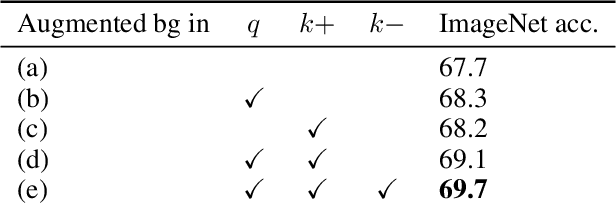
Unsupervised representation learning is an important challenge in computer vision, with self-supervised learning methods recently closing the gap to supervised representation learning. An important ingredient in high-performing self-supervised methods is the use of data augmentation by training models to place different augmented views of the same image nearby in embedding space. However, commonly used augmentation pipelines treat images holistically, disregarding the semantic relevance of parts of an image-e.g. a subject vs. a background-which can lead to the learning of spurious correlations. Our work addresses this problem by investigating a class of simple, yet highly effective "background augmentations", which encourage models to focus on semantically-relevant content by discouraging them from focusing on image backgrounds. Background augmentations lead to substantial improvements (+1-2% on ImageNet-1k) in performance across a spectrum of state-of-the art self-supervised methods (MoCov2, BYOL, SwAV) on a variety of tasks, allowing us to reach within 0.3% of supervised performance. We also demonstrate that background augmentations improve robustness to a number of out of distribution settings, including natural adversarial examples, the backgrounds challenge, adversarial attacks, and ReaL ImageNet.
Can a Fruit Fly Learn Word Embeddings?
Jan 18, 2021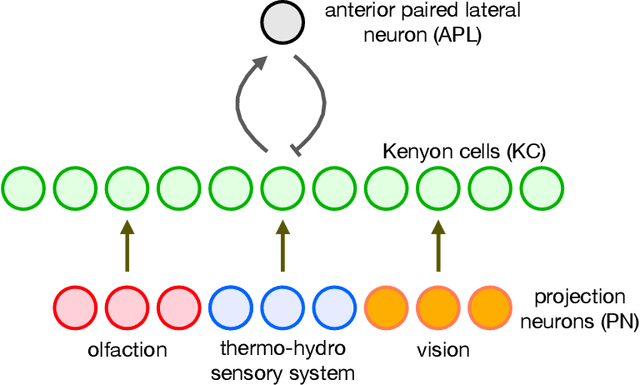
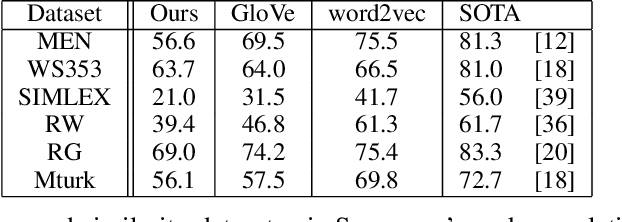
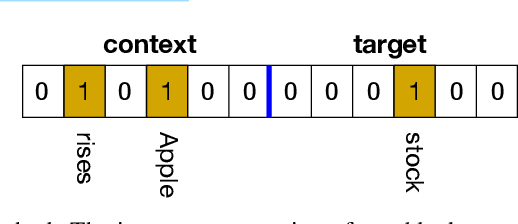

The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
Bio-Inspired Hashing for Unsupervised Similarity Search
Jan 14, 2020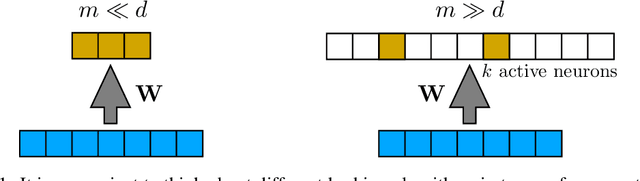
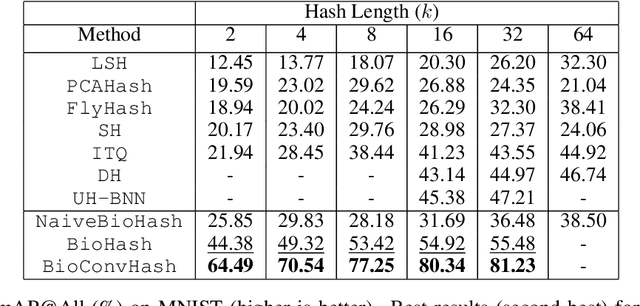
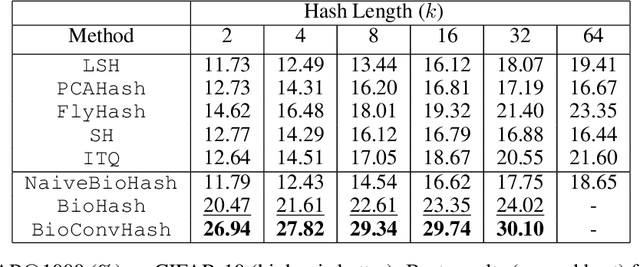
The fruit fly Drosophila's olfactory circuit has inspired a new locality sensitive hashing (LSH) algorithm, FlyHash. In contrast with classical LSH algorithms that produce low dimensional hash codes, FlyHash produces sparse high-dimensional hash codes and has also been shown to have superior empirical performance compared to classical LSH algorithms in similarity search. However, FlyHash uses random projections and cannot learn from data. Building on inspiration from FlyHash and the ubiquity of sparse expansive representations in neurobiology, our work proposes a novel hashing algorithm BioHash that produces sparse high dimensional hash codes in a data-driven manner. We show that BioHash outperforms previously published benchmarks for various hashing methods. Since our learning algorithm is based on a local and biologically plausible synaptic plasticity rule, our work provides evidence for the proposal that LSH might be a computational reason for the abundance of sparse expansive motifs in a variety of biological systems. We also propose a convolutional variant BioConvHash that further improves performance. From the perspective of computer science, BioHash and BioConvHash are fast, scalable and yield compressed binary representations that are useful for similarity search.