 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic insights on continual learning from fruit flies
Jul 15, 2021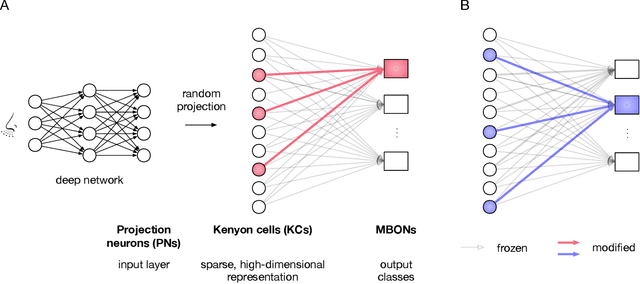
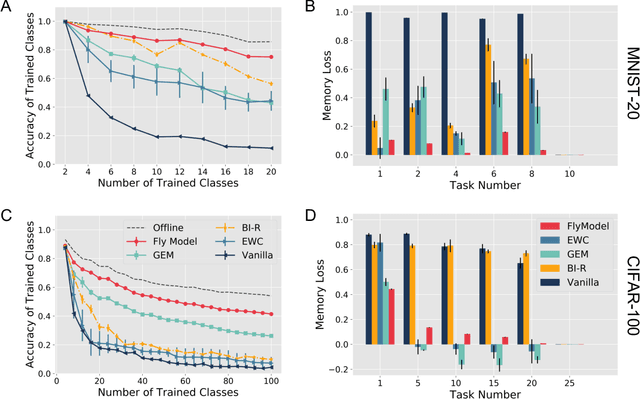
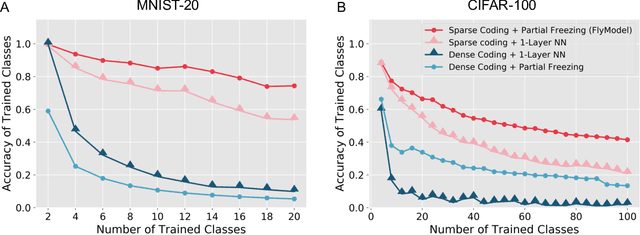
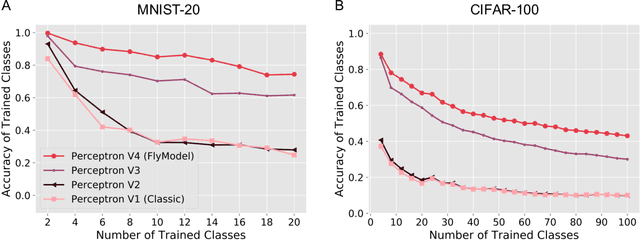
Continual learning in computational systems is challenging due to catastrophic forgetting. We discovered a two layer neural circuit in the fruit fly olfactory system that addresses this challenge by uniquely combining sparse coding and associative learning. In the first layer, odors are encoded using sparse, high dimensional representations, which reduces memory interference by activating non overlapping populations of neurons for different odors. In the second layer, only the synapses between odor activated neurons and the output neuron associated with the odor are modified during learning; the rest of the weights are frozen to prevent unrelated memories from being overwritten. We show empirically and analytically that this simple and lightweight algorithm significantly boosts continual learning performance. The fly associative learning algorithm is strikingly similar to the classic perceptron learning algorithm, albeit two modifications, which we show are critical for reducing catastrophic forgetting. Overall, fruit flies evolved an efficient lifelong learning algorithm, and circuit mechanisms from neuroscience can be translated to improve machine computation.
Can a Fruit Fly Learn Word Embeddings?
Jan 18, 2021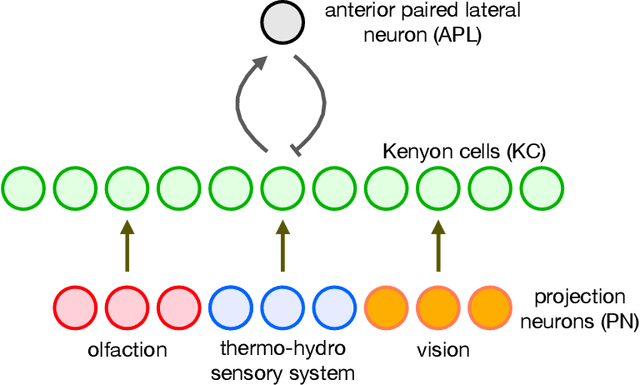
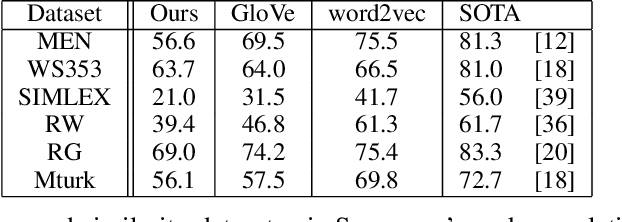
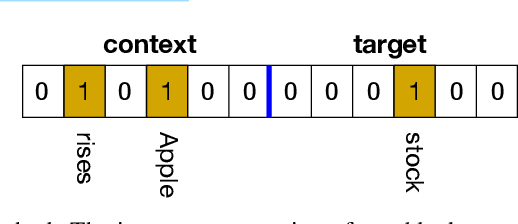

The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
Improving Similarity Search with High-dimensional Locality-sensitive Hashing
Dec 05, 2018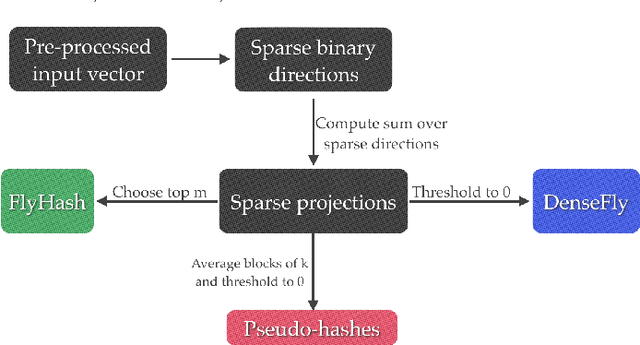
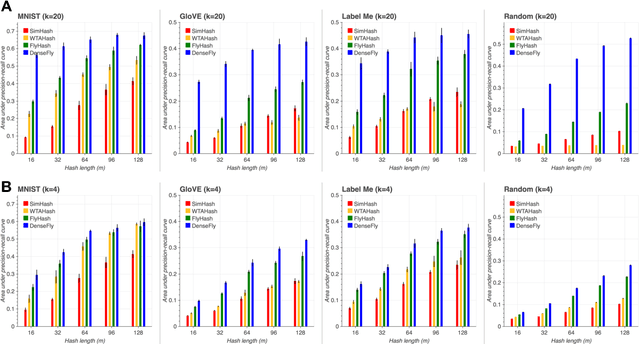
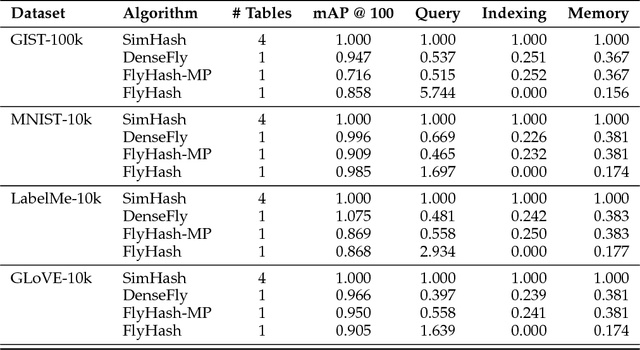
We propose a new class of data-independent locality-sensitive hashing (LSH) algorithms based on the fruit fly olfactory circuit. The fundamental difference of this approach is that, instead of assigning hashes as dense points in a low dimensional space, hashes are assigned in a high dimensional space, which enhances their separability. We show theoretically and empirically that this new family of hash functions is locality-sensitive and preserves rank similarity for inputs in any `p space. We then analyze different variations on this strategy and show empirically that they outperform existing LSH methods for nearest-neighbors search on six benchmark datasets. Finally, we propose a multi-probe version of our algorithm that achieves higher performance for the same query time, or conversely, that maintains performance of prior approaches while taking significantly less indexing time and memory. Overall, our approach leverages the advantages of separability provided by high-dimensional spaces, while still remaining computationally efficient
Using inspiration from synaptic plasticity rules to optimize traffic flow in distributed engineered networks
Nov 21, 2016Controlling the flow and routing of data is a fundamental problem in many distributed networks, including transportation systems, integrated circuits, and the Internet. In the brain, synaptic plasticity rules have been discovered that regulate network activity in response to environmental inputs, which enable circuits to be stable yet flexible. Here, we develop a new neuro-inspired model for network flow control that only depends on modifying edge weights in an activity-dependent manner. We show how two fundamental plasticity rules (long-term potentiation and long-term depression) can be cast as a distributed gradient descent algorithm for regulating traffic flow in engineered networks. We then characterize, both via simulation and analytically, how different forms of edge-weight update rules affect network routing efficiency and robustness. We find a close correspondence between certain classes of synaptic weight update rules derived experimentally in the brain and rules commonly used in engineering, suggesting common principles to both.
* 43 pages, 5 Figures. Submitted to Neural Computation