 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding temperature tuning in energy-based models
Dec 09, 2025Generative models of complex systems often require post-hoc parameter adjustments to produce useful outputs. For example, energy-based models for protein design are sampled at an artificially low ''temperature'' to generate novel, functional sequences. This temperature tuning is a common yet poorly understood heuristic used across machine learning contexts to control the trade-off between generative fidelity and diversity. Here, we develop an interpretable, physically motivated framework to explain this phenomenon. We demonstrate that in systems with a large ''energy gap'' - separating a small fraction of meaningful states from a vast space of unrealistic states - learning from sparse data causes models to systematically overestimate high-energy state probabilities, a bias that lowering the sampling temperature corrects. More generally, we characterize how the optimal sampling temperature depends on the interplay between data size and the system's underlying energy landscape. Crucially, our results show that lowering the sampling temperature is not always desirable; we identify the conditions where \emph{raising} it results in better generative performance. Our framework thus casts post-hoc temperature tuning as a diagnostic tool that reveals properties of the true data distribution and the limits of the learned model.
Data coarse graining can improve model performance
Sep 18, 2025Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under 'data coarse graining.' Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A 'high-pass' scheme--which filters out less relevant, lower-signal features--can help models generalize better. By contrast, a 'low-pass' scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.
When can in-context learning generalize out of task distribution?
Jun 05, 2025In-context learning (ICL) is a remarkable capability of pretrained transformers that allows models to generalize to unseen tasks after seeing only a few examples. We investigate empirically the conditions necessary on the pretraining distribution for ICL to emerge and generalize \emph{out-of-distribution}. Previous work has focused on the number of distinct tasks necessary in the pretraining dataset. Here, we use a different notion of task diversity to study the emergence of ICL in transformers trained on linear functions. We find that as task diversity increases, transformers undergo a transition from a specialized solution, which exhibits ICL only within the pretraining task distribution, to a solution which generalizes out of distribution to the entire task space. We also investigate the nature of the solutions learned by the transformer on both sides of the transition, and observe similar transitions in nonlinear regression problems. We construct a phase diagram to characterize how our concept of task diversity interacts with the number of pretraining tasks. In addition, we explore how factors such as the depth of the model and the dimensionality of the regression problem influence the transition.
Generalized Information Bottleneck for Gaussian Variables
Mar 31, 2023

The information bottleneck (IB) method offers an attractive framework for understanding representation learning, however its applications are often limited by its computational intractability. Analytical characterization of the IB method is not only of practical interest, but it can also lead to new insights into learning phenomena. Here we consider a generalized IB problem, in which the mutual information in the original IB method is replaced by correlation measures based on Renyi and Jeffreys divergences. We derive an exact analytical IB solution for the case of Gaussian correlated variables. Our analysis reveals a series of structural transitions, similar to those previously observed in the original IB case. We find further that although solving the original, Renyi and Jeffreys IB problems yields different representations in general, the structural transitions occur at the same critical tradeoff parameters, and the Renyi and Jeffreys IB solutions perform well under the original IB objective. Our results suggest that formulating the IB method with alternative correlation measures could offer a strategy for obtaining an approximate solution to the original IB problem.
Information bottleneck theory of high-dimensional regression: relevancy, efficiency and optimality
Aug 08, 2022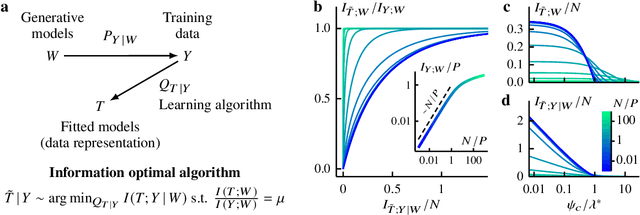
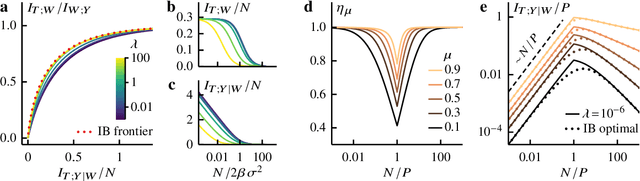
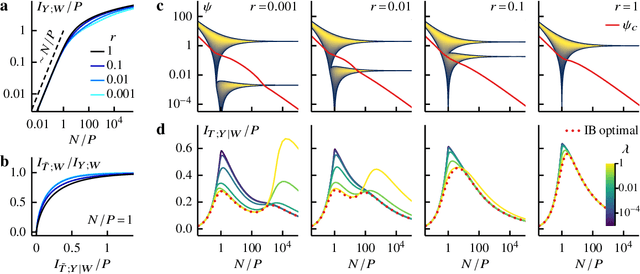
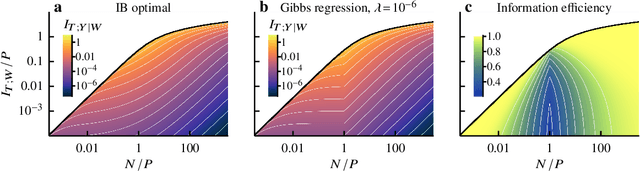
Avoiding overfitting is a central challenge in machine learning, yet many large neural networks readily achieve zero training loss. This puzzling contradiction necessitates new approaches to the study of overfitting. Here we quantify overfitting via residual information, defined as the bits in fitted models that encode noise in training data. Information efficient learning algorithms minimize residual information while maximizing the relevant bits, which are predictive of the unknown generative models. We solve this optimization to obtain the information content of optimal algorithms for a linear regression problem and compare it to that of randomized ridge regression. Our results demonstrate the fundamental tradeoff between residual and relevant information and characterize the relative information efficiency of randomized regression with respect to optimal algorithms. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil information-theoretic analogs of double and multiple descent phenomena.
Perturbation Theory for the Information Bottleneck
May 28, 2021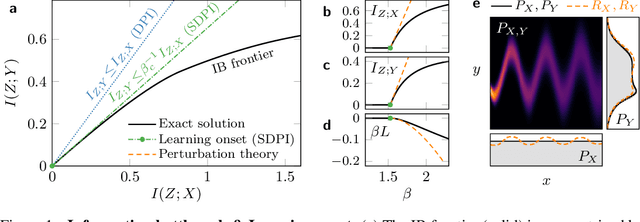
Extracting relevant information from data is crucial for all forms of learning. The information bottleneck (IB) method formalizes this, offering a mathematically precise and conceptually appealing framework for understanding learning phenomena. However the nonlinearity of the IB problem makes it computationally expensive and analytically intractable in general. Here we derive a perturbation theory for the IB method and report the first complete characterization of the learning onset, the limit of maximum relevant information per bit extracted from data. We test our results on synthetic probability distributions, finding good agreement with the exact numerical solution near the onset of learning. We explore the difference and subtleties in our derivation and previous attempts at deriving a perturbation theory for the learning onset and attribute the discrepancy to a flawed assumption. Our work also provides a fresh perspective on the intimate relationship between the IB method and the strong data processing inequality.