 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs
Paper and Code
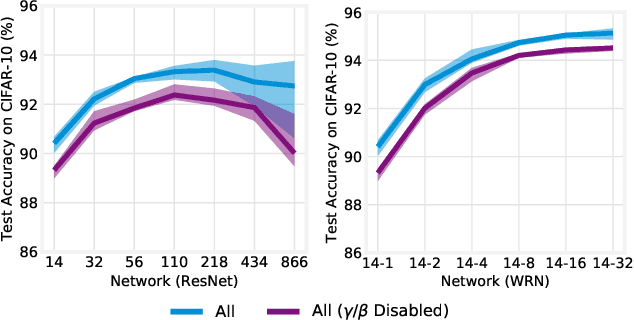
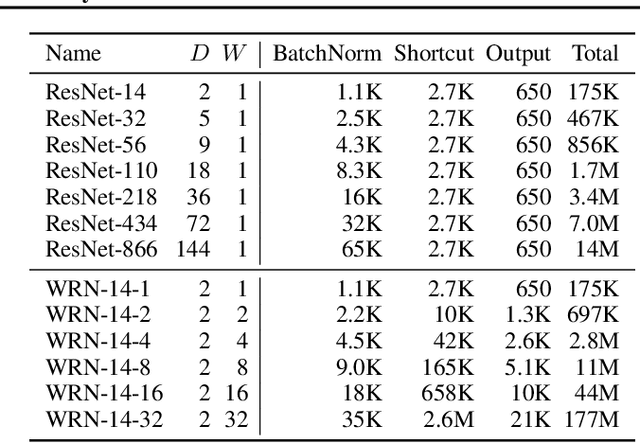
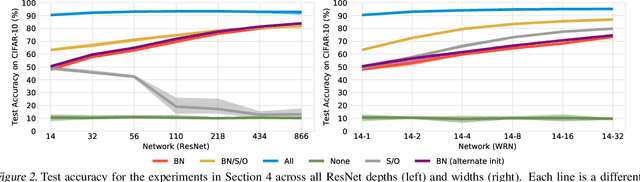
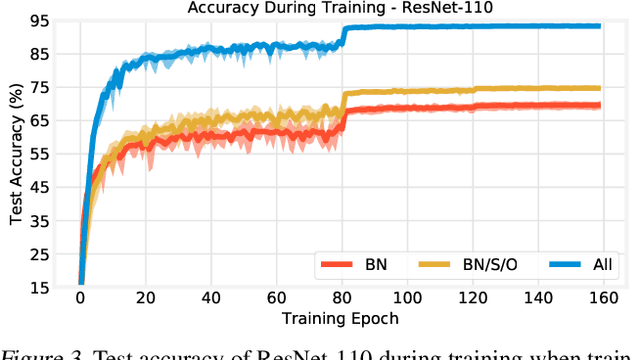
Batch normalization (BatchNorm) has become an indispensable tool for training deep neural networks, yet it is still poorly understood. Although previous work has typically focused on its normalization component, BatchNorm also adds two per-feature trainable parameters: a coefficient and a bias. However, the role and expressive power of these parameters remains unclear. To study this question, we investigate the performance achieved when training only these parameters and freezing all others at their random initializations. We find that doing so leads to surprisingly high performance. For example, a sufficiently deep ResNet reaches 83% accuracy on CIFAR-10 in this configuration. Interestingly, BatchNorm achieves this performance in part by naturally learning to disable around a third of the random features without any changes to the training objective. Not only do these results highlight the under-appreciated role of the affine parameters in BatchNorm, but - in a broader sense - they characterize the expressive power of neural networks constructed simply by shifting and rescaling random features.