 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-variance decomposition of overparameterized regression with random linear features
Paper and Code
Mar 10, 2022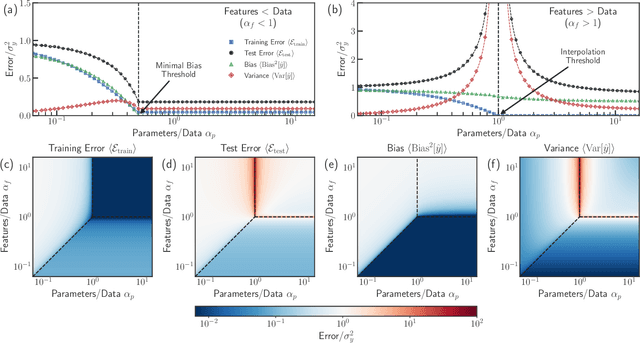
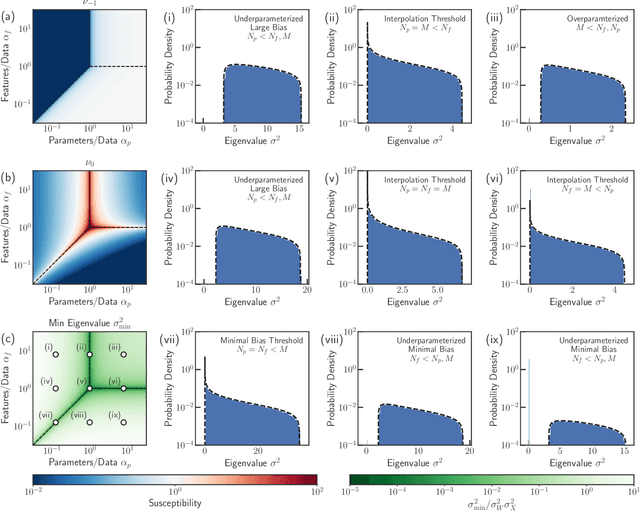
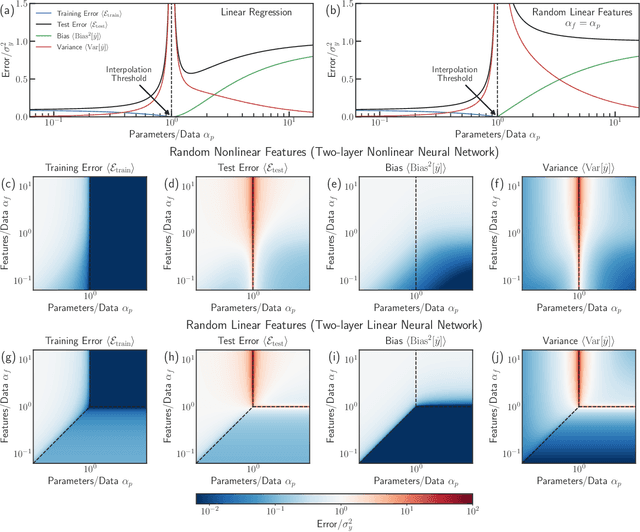
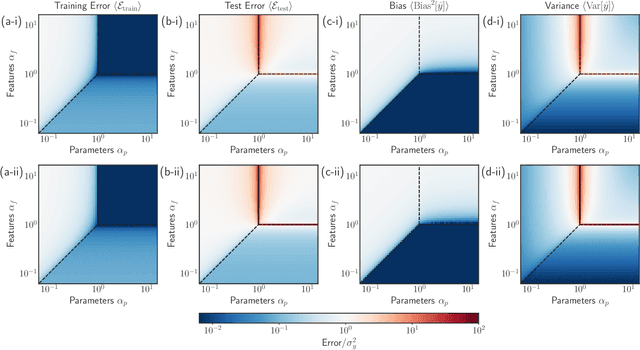
In classical statistics, the bias-variance trade-off describes how varying a model's complexity (e.g., number of fit parameters) affects its ability to make accurate predictions. According to this trade-off, optimal performance is achieved when a model is expressive enough to capture trends in the data, yet not so complex that it overfits idiosyncratic features of the training data. Recently, it has become clear that this classic understanding of the bias-variance must be fundamentally revisited in light of the incredible predictive performance of "overparameterized models" -- models that avoid overfitting even when the number of fit parameters is large enough to perfectly fit the training data. Here, we present results for one of the simplest examples of an overparameterized model: regression with random linear features (i.e. a two-layer neural network with a linear activation function). Using the zero-temperature cavity method, we derive analytic expressions for the training error, test error, bias, and variance. We show that the linear random features model exhibits three phase transitions: two different transitions to an interpolation regime where the training error is zero, along with an additional transition between regimes with large bias and minimal bias. Using random matrix theory, we show how each transition arises due to small nonzero eigenvalues in the Hessian matrix. Finally, we compare and contrast the phase diagram of the random linear features model to the random nonlinear features model and ordinary regression, highlighting the new phase transitions that result from the use of linear basis functions.