 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorizing without overfitting: Bias, variance, and interpolation in over-parameterized models
Paper and Code
Oct 26, 2020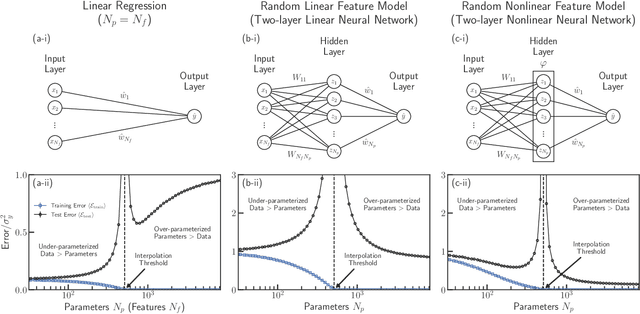
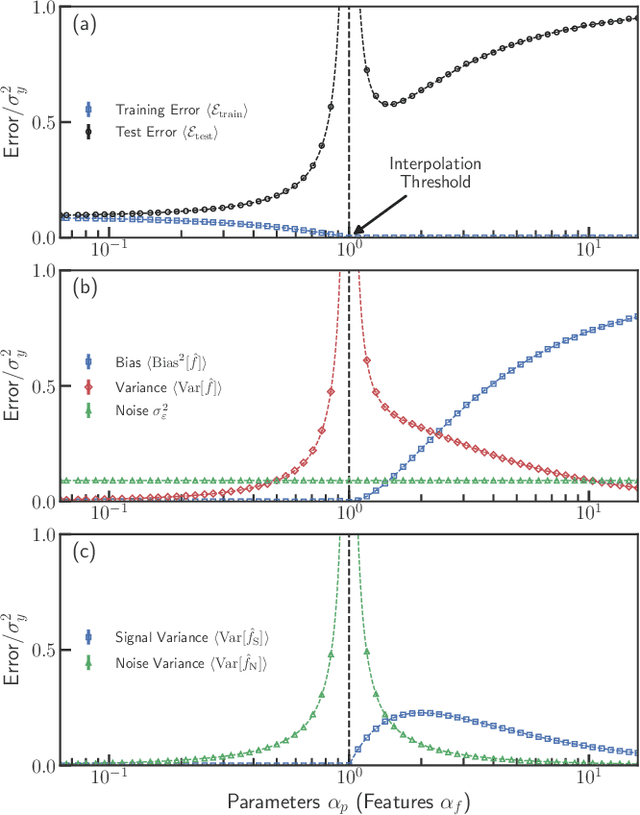
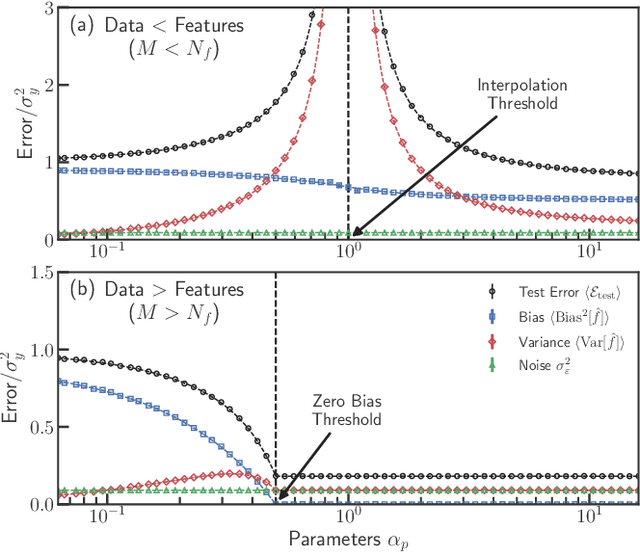
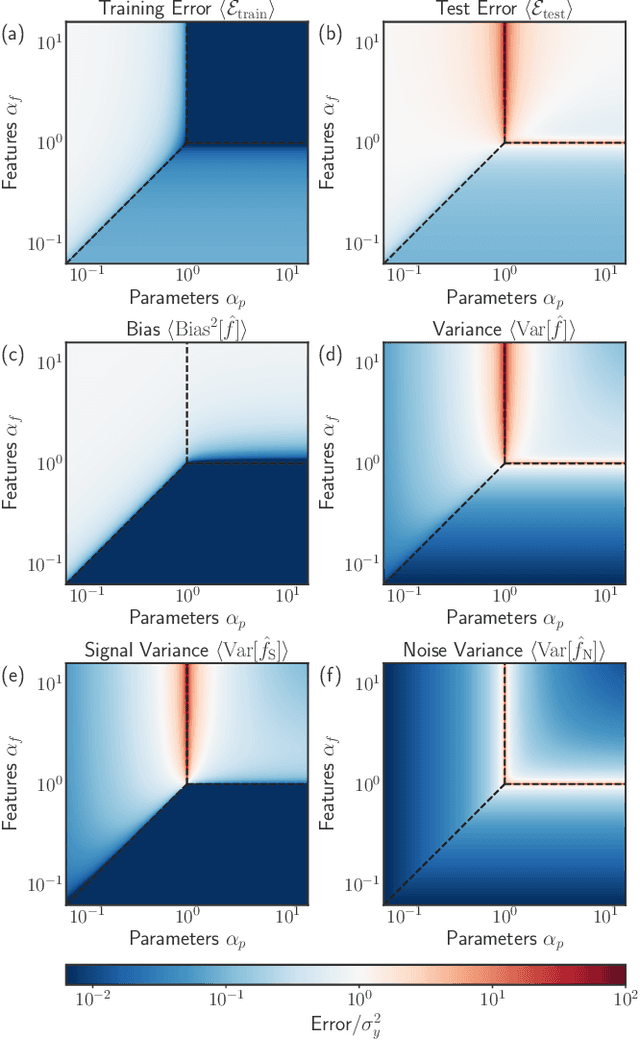
The bias-variance trade-off is a central concept in supervised learning. In classical statistics, increasing the complexity of a model (e.g., number of parameters) reduces bias but also increases variance. Until recently, it was commonly believed that optimal performance is achieved at intermediate model complexities which strike a balance between bias and variance. Modern Deep Learning methods flout this dogma, achieving state-of-the-art performance using "over-parameterized models" where the number of fit parameters is large enough to perfectly fit the training data. As a result, understanding bias and variance in over-parameterized models has emerged as a fundamental problem in machine learning. Here, we use methods from statistical physics to derive analytic expressions for bias and variance in three minimal models for over-parameterization (linear regression and two-layer neural networks with linear and nonlinear activation functions), allowing us to disentangle properties stemming from the model architecture and random sampling of data. All three models exhibit a phase transition to an interpolation regime where the training error is zero, with linear neural-networks possessing an additional phase transition between regimes with zero and nonzero bias. The test error diverges at the interpolation transition for all three models. However, beyond the transition, it decreases again for the neural network models due to a decrease in both bias and variance with model complexity. We also show that over-parameterized models can overfit even in the absence of noise. We synthesize these results to construct a holistic understanding of generalization error and the bias-variance trade-off in over-parameterized models.