 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-directed sampling for bandits: a primer
Dec 23, 2025The Multi-Armed Bandit problem provides a fundamental framework for analyzing the tension between exploration and exploitation in sequential learning. This paper explores Information Directed Sampling (IDS) policies, a class of heuristics that balance immediate regret against information gain. We focus on the tractable environment of two-state Bernoulli bandits as a minimal model to rigorously compare heuristic strategies against the optimal policy. We extend the IDS framework to the discounted infinite-horizon setting by introducing a modified information measure and a tuning parameter to modulate the decision-making behavior. We examine two specific problem classes: symmetric bandits and the scenario involving one fair coin. In the symmetric case we show that IDS achieves bounded cumulative regret, whereas in the one-fair-coin scenario the IDS policy yields a regret that scales logarithmically with the horizon, in agreement with classical asymptotic lower bounds. This work serves as a pedagogical synthesis, aiming to bridge concepts from reinforcement learning and information theory for an audience of statistical physicists.
Harvesting energy from turbulent winds with Reinforcement Learning
Dec 18, 2024



Airborne Wind Energy (AWE) is an emerging technology designed to harness the power of high-altitude winds, offering a solution to several limitations of conventional wind turbines. AWE is based on flying devices (usually gliders or kites) that, tethered to a ground station and driven by the wind, convert its mechanical energy into electrical energy by means of a generator. Such systems are usually controlled by manoeuvering the kite so as to follow a predefined path prescribed by optimal control techniques, such as model-predictive control. These methods are strongly dependent on the specific model at use and difficult to generalize, especially in unpredictable conditions such as the turbulent atmospheric boundary layer. Our aim is to explore the possibility of replacing these techniques with an approach based on Reinforcement Learning (RL). Unlike traditional methods, RL does not require a predefined model, making it robust to variability and uncertainty. Our experimental results in complex simulated environments demonstrate that AWE agents trained with RL can effectively extract energy from turbulent flows, relying on minimal local information about the kite orientation and speed relative to the wind.
Taming Lagrangian Chaos with Multi-Objective Reinforcement Learning
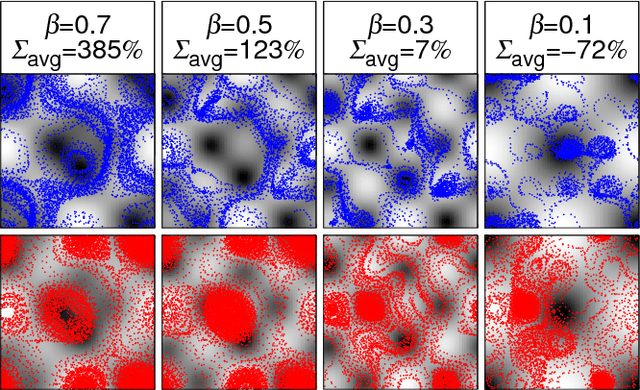
Dec 19, 2022We consider the problem of two active particles in 2D complex flows with the multi-objective goals of minimizing both the dispersion rate and the energy consumption of the pair. We approach the problem by means of Multi Objective Reinforcement Learning (MORL), combining scalarization techniques together with a Q-learning algorithm, for Lagrangian drifters that have variable swimming velocity. We show that MORL is able to find a set of trade-off solutions forming an optimal Pareto frontier. As a benchmark, we show that a set of heuristic strategies are dominated by the MORL solutions. We consider the situation in which the agents cannot update their control variables continuously, but only after a discrete (decision) time, $\tau$. We show that there is a range of decision times, in between the Lyapunov time and the continuous updating limit, where Reinforcement Learning finds strategies that significantly improve over heuristics. In particular, we discuss how large decision times require enhanced knowledge of the flow, whereas for smaller $\tau$ all a priori heuristic strategies become Pareto optimal.
Reinforcement learning for pursuit and evasion of microswimmers at low Reynolds number
Jun 16, 2021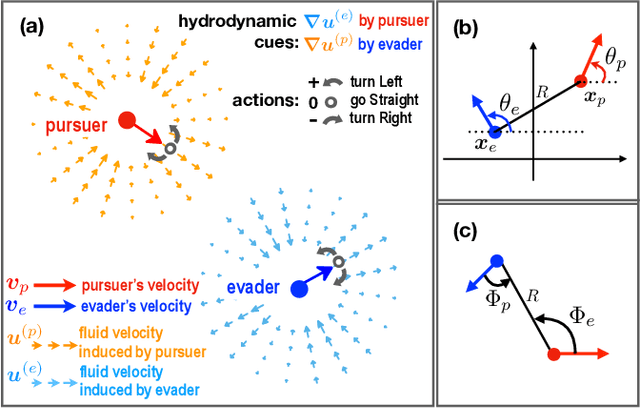
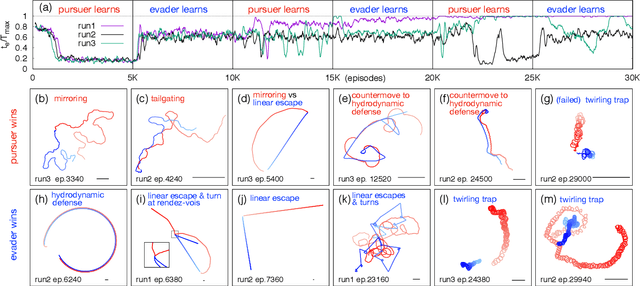
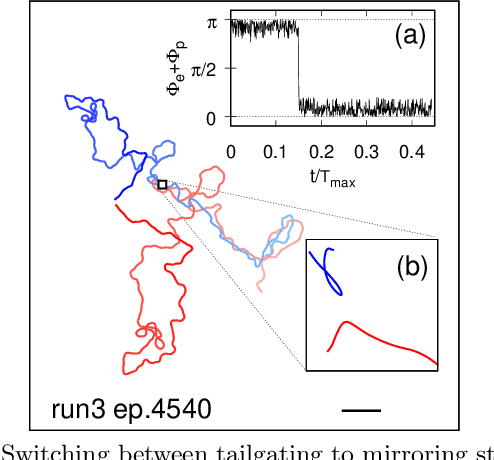
Aquatic organisms can use hydrodynamic cues to navigate, find their preys and escape from predators. We consider a model of two competing microswimmers engaged in a pursue-evasion task while immersed in a low-Reynolds-number environment. The players have limited abilities: they can only sense hydrodynamic disturbances, which provide some cue about the opponent's position, and perform simple manoeuvres. The goal of the pursuer is to capturethe evader in the shortest possible time. Conversely the evader aims at deferring capture as much as possible. We show that by means of Reinforcement Learning the players find efficient and physically explainable strategies which non-trivially exploit the hydrodynamic environment. This Letter offers a proof-of-concept for the use of Reinforcement Learning to discover prey-predator strategies in aquatic environments, with potential applications to underwater robotics.
Flow Navigation by Smart Microswimmers via Reinforcement Learning
Jul 26, 2017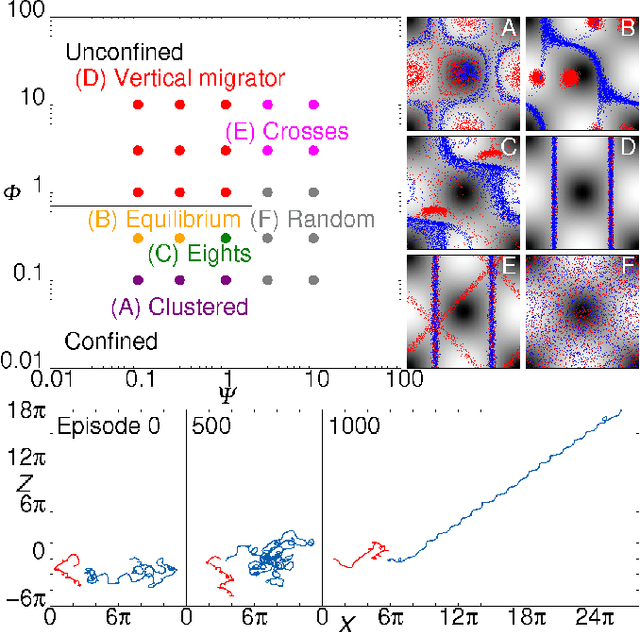
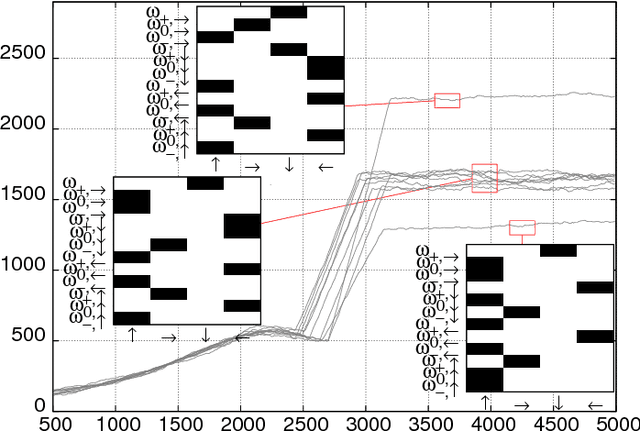
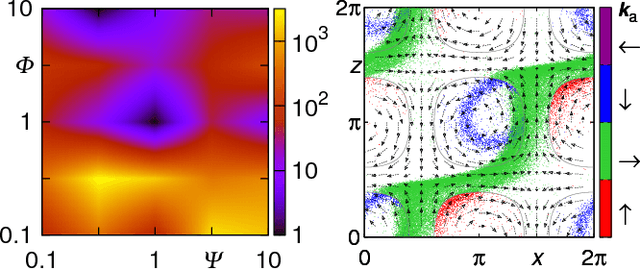
Smart active particles can acquire some limited knowledge of the fluid environment from simple mechanical cues and exert a control on their preferred steering direction. Their goal is to learn the best way to navigate by exploiting the underlying flow whenever possible. As an example, we focus our attention on smart gravitactic swimmers. These are active particles whose task is to reach the highest altitude within some time horizon, given the constraints enforced by fluid mechanics. By means of numerical experiments, we show that swimmers indeed learn nearly optimal strategies just by experience. A reinforcement learning algorithm allows particles to learn effective strategies even in difficult situations when, in the absence of control, they would end up being trapped by flow structures. These strategies are highly nontrivial and cannot be easily guessed in advance. This Letter illustrates the potential of reinforcement learning algorithms to model adaptive behavior in complex flows and paves the way towards the engineering of smart microswimmers that solve difficult navigation problems.
* Published on Physical Review Letters (April 12, 2017)
Infomax strategies for an optimal balance between exploration and exploitation
Jan 12, 2016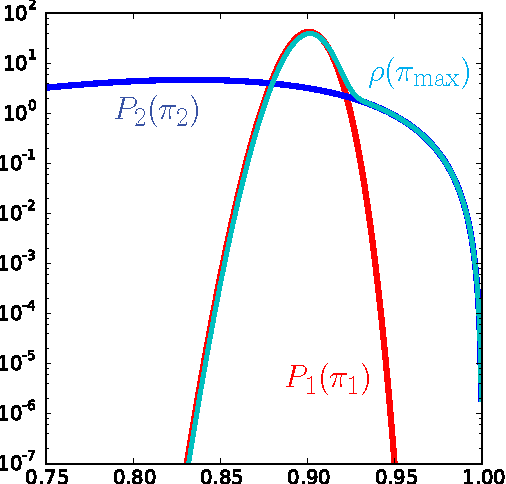
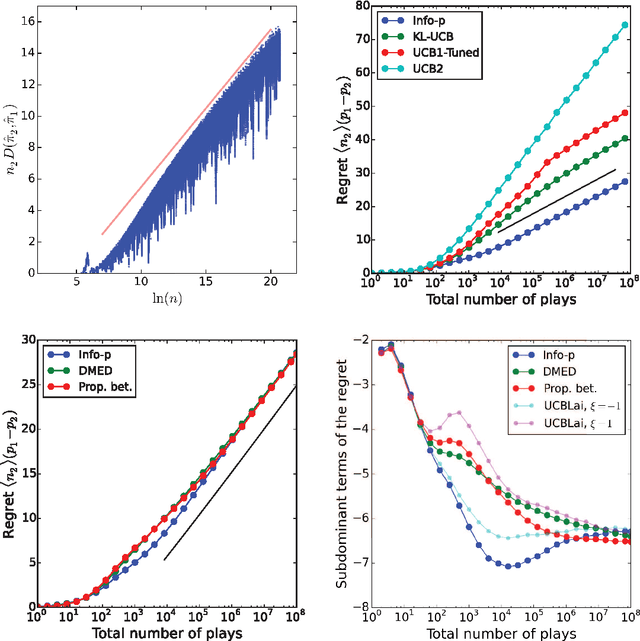
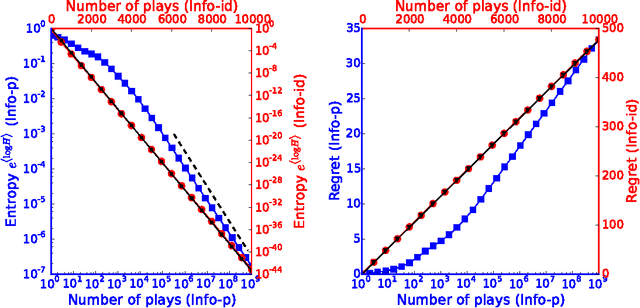
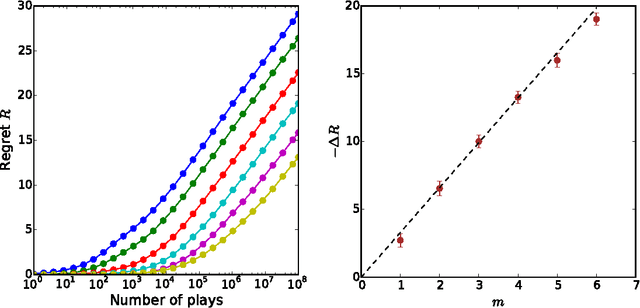
Proper balance between exploitation and exploration is what makes good decisions, which achieve high rewards like payoff or evolutionary fitness. The Infomax principle postulates that maximization of information directs the function of diverse systems, from living systems to artificial neural networks. While specific applications are successful, the validity of information as a proxy for reward remains unclear. Here, we consider the multi-armed bandit decision problem, which features arms (slot-machines) of unknown probabilities of success and a player trying to maximize cumulative payoff by choosing the sequence of arms to play. We show that an Infomax strategy (Info-p) which optimally gathers information on the highest mean reward among the arms saturates known optimal bounds and compares favorably to existing policies. The highest mean reward considered by Info-p is not the quantity actually needed for the choice of the arm to play, yet it allows for optimal tradeoffs between exploration and exploitation.