 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential learning kinetics govern the transition from memorization to generalization during in-context learning
Paper and Code
Nov 27, 2024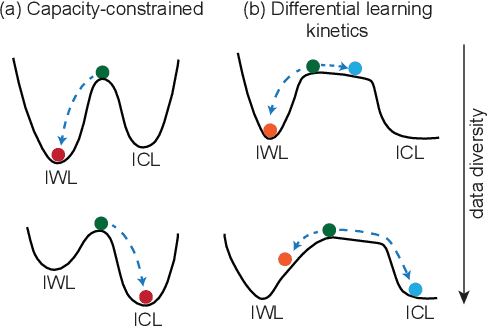
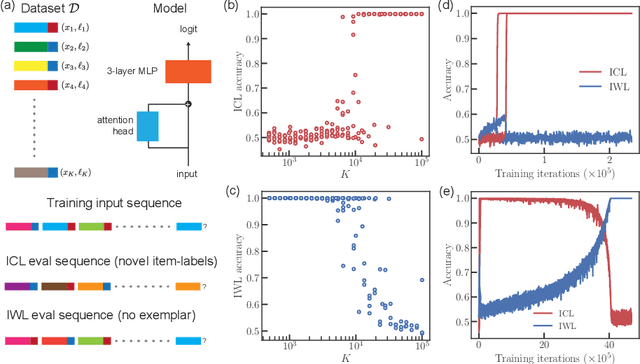
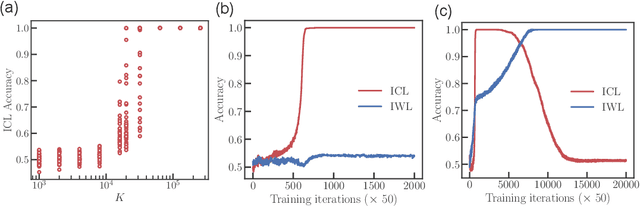
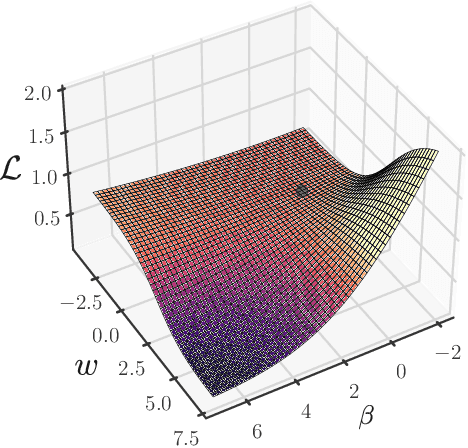
Transformers exhibit in-context learning (ICL): the ability to use novel information presented in the context without additional weight updates. Recent work shows that ICL emerges when models are trained on a sufficiently diverse set of tasks and the transition from memorization to generalization is sharp with increasing task diversity. One interpretation is that a network's limited capacity to memorize favors generalization. Here, we examine the mechanistic underpinnings of this transition using a small transformer applied to a synthetic ICL task. Using theory and experiment, we show that the sub-circuits that memorize and generalize can be viewed as largely independent. The relative rates at which these sub-circuits learn explains the transition from memorization to generalization, rather than capacity constraints. We uncover a memorization scaling law, which determines the task diversity threshold at which the network generalizes. The theory quantitatively explains a variety of other ICL-related phenomena, including the long-tailed distribution of when ICL is acquired, the bimodal behavior of solutions close to the task diversity threshold, the influence of contextual and data distributional statistics on ICL, and the transient nature of ICL.