Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscoders Beat Sparse Autoencoders for Interpretability
Paper and Code
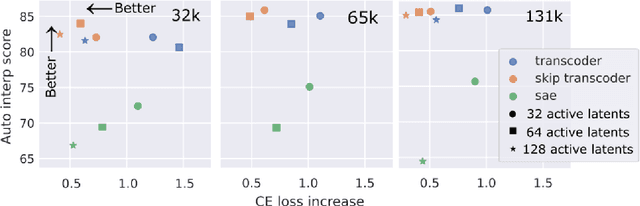

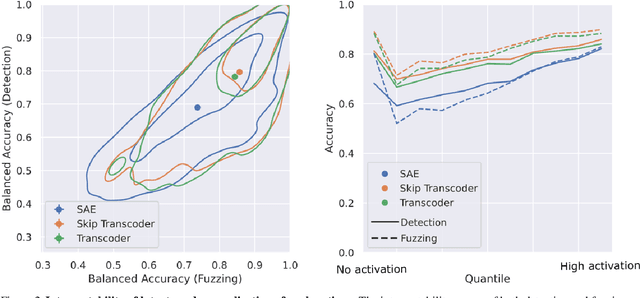

Sparse autoencoders (SAEs) extract human-interpretable features from deep neural networks by transforming their activations into a sparse, higher dimensional latent space, and then reconstructing the activations from these latents. Transcoders are similar to SAEs, but they are trained to reconstruct the output of a component of a deep network given its input. In this work, we compare the features found by transcoders and SAEs trained on the same model and data, finding that transcoder features are significantly more interpretable. We also propose _skip transcoders_, which add an affine skip connection to the transcoder architecture, and show that these achieve lower reconstruction loss with no effect on interpretability.
View paper on