 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Compositional Awareness in CLIP with Efficient Fine-Tuning
May 30, 2025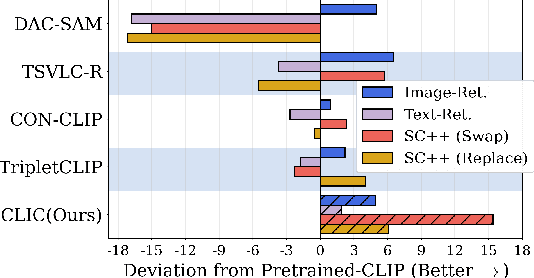
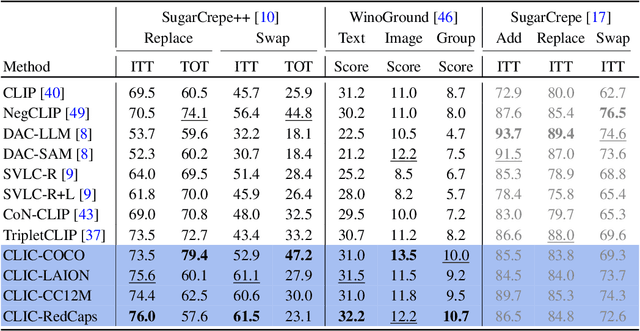

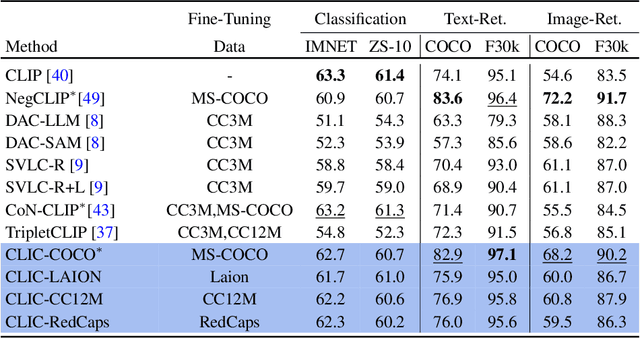
Vision-language models like CLIP have demonstrated remarkable zero-shot capabilities in classification and retrieval. However, these models often struggle with compositional reasoning - the ability to understand the relationships between concepts. A recent benchmark, SugarCrepe++, reveals that previous works on improving compositionality have mainly improved lexical sensitivity but neglected semantic understanding. In addition, downstream retrieval performance often deteriorates, although one would expect that improving compositionality should enhance retrieval. In this work, we introduce CLIC (Compositionally-aware Learning in CLIP), a fine-tuning method based on a novel training technique combining multiple images and their associated captions. CLIC improves compositionality across architectures as well as differently pre-trained CLIP models, both in terms of lexical and semantic understanding, and achieves consistent gains in retrieval performance. This even applies to the recent CLIPS, which achieves SOTA retrieval performance. Nevertheless, the short fine-tuning with CLIC leads to an improvement in retrieval and to the best compositional CLIP model on SugarCrepe++. All our models and code are available at https://clic-compositional-clip.github.io
Adversarially Robust CLIP Models Can Induce Better (Robust) Perceptual Metrics
Feb 17, 2025



Measuring perceptual similarity is a key tool in computer vision. In recent years perceptual metrics based on features extracted from neural networks with large and diverse training sets, e.g. CLIP, have become popular. At the same time, the metrics extracted from features of neural networks are not adversarially robust. In this paper we show that adversarially robust CLIP models, called R-CLIP$_\textrm{F}$, obtained by unsupervised adversarial fine-tuning induce a better and adversarially robust perceptual metric that outperforms existing metrics in a zero-shot setting, and further matches the performance of state-of-the-art metrics while being robust after fine-tuning. Moreover, our perceptual metric achieves strong performance on related tasks such as robust image-to-image retrieval, which becomes especially relevant when applied to "Not Safe for Work" (NSFW) content detection and dataset filtering. While standard perceptual metrics can be easily attacked by a small perturbation completely degrading NSFW detection, our robust perceptual metric maintains high accuracy under an attack while having similar performance for unperturbed images. Finally, perceptual metrics induced by robust CLIP models have higher interpretability: feature inversion can show which images are considered similar, while text inversion can find what images are associated to a given prompt. This also allows us to visualize the very rich visual concepts learned by a CLIP model, including memorized persons, paintings and complex queries.
Perturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP
Dec 01, 2024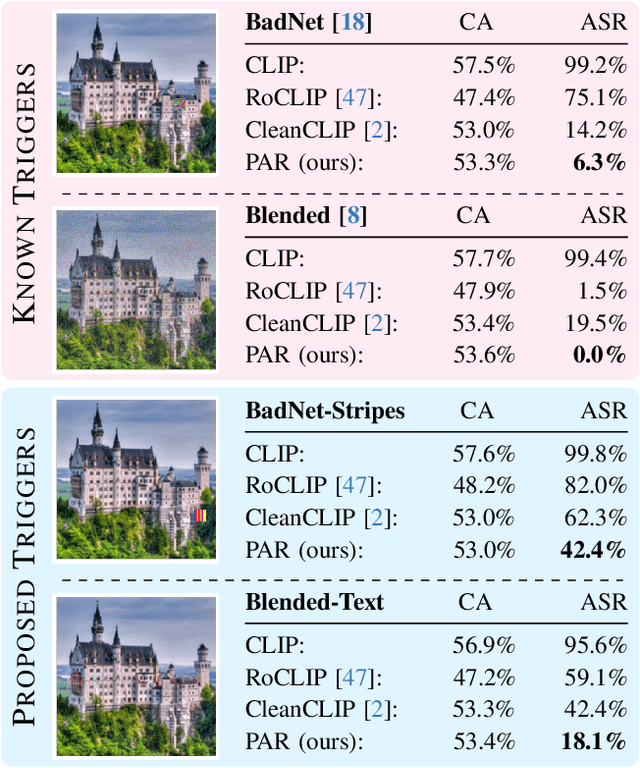
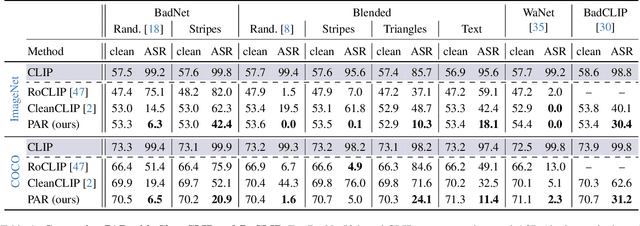

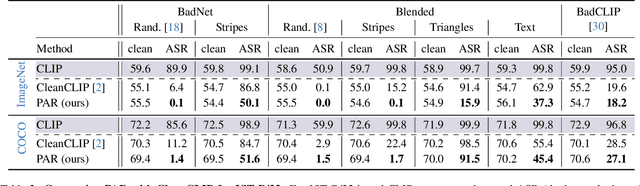
Vision-Language models like CLIP have been shown to be highly effective at linking visual perception and natural language understanding, enabling sophisticated image-text capabilities, including strong retrieval and zero-shot classification performance. Their widespread use, as well as the fact that CLIP models are trained on image-text pairs from the web, make them both a worthwhile and relatively easy target for backdoor attacks. As training foundational models, such as CLIP, from scratch is very expensive, this paper focuses on cleaning potentially poisoned models via fine-tuning. We first show that existing cleaning techniques are not effective against simple structured triggers used in Blended or BadNet backdoor attacks, exposing a critical vulnerability for potential real-world deployment of these models. Then, we introduce PAR, Perturb and Recover, a surprisingly simple yet effective mechanism to remove backdoors from CLIP models. Through extensive experiments across different encoders and types of backdoor attacks, we show that PAR achieves high backdoor removal rate while preserving good standard performance. Finally, we illustrate that our approach is effective even only with synthetic text-image pairs, i.e. without access to real training data. The code and models are available at \href{https://github.com/nmndeep/PerturbAndRecover}{https://github.com/nmndeep/PerturbAndRecover}.
Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Feb 19, 2024



Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many vision-language models (VLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (VLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of VLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the VLM is required. The code and robust models are available at https://github.com/chs20/RobustVLM