 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP
Paper and Code
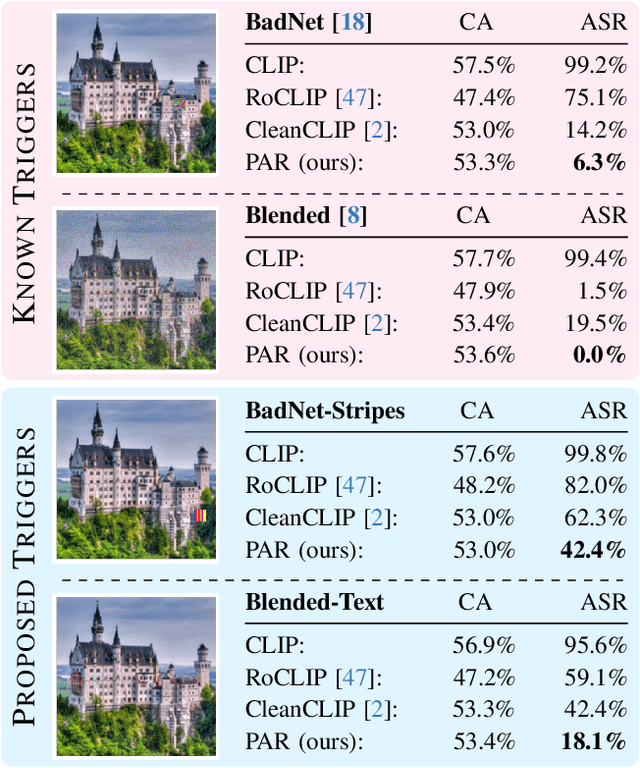
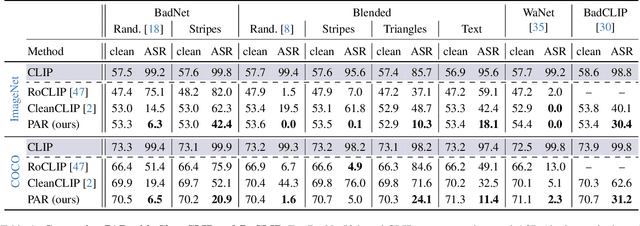

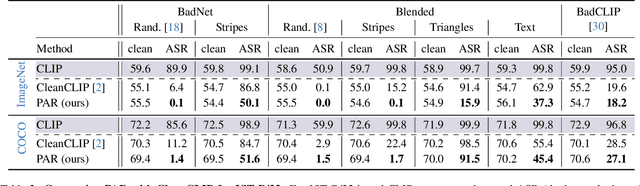
Vision-Language models like CLIP have been shown to be highly effective at linking visual perception and natural language understanding, enabling sophisticated image-text capabilities, including strong retrieval and zero-shot classification performance. Their widespread use, as well as the fact that CLIP models are trained on image-text pairs from the web, make them both a worthwhile and relatively easy target for backdoor attacks. As training foundational models, such as CLIP, from scratch is very expensive, this paper focuses on cleaning potentially poisoned models via fine-tuning. We first show that existing cleaning techniques are not effective against simple structured triggers used in Blended or BadNet backdoor attacks, exposing a critical vulnerability for potential real-world deployment of these models. Then, we introduce PAR, Perturb and Recover, a surprisingly simple yet effective mechanism to remove backdoors from CLIP models. Through extensive experiments across different encoders and types of backdoor attacks, we show that PAR achieves high backdoor removal rate while preserving good standard performance. Finally, we illustrate that our approach is effective even only with synthetic text-image pairs, i.e. without access to real training data. The code and models are available at \href{https://github.com/nmndeep/PerturbAndRecover}{https://github.com/nmndeep/PerturbAndRecover}.