 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Often Know When They Are Being Evaluated
May 28, 2025If AI models can detect when they are being evaluated, the effectiveness of evaluations might be compromised. For example, models could have systematically different behavior during evaluations, leading to less reliable benchmarks for deployment and governance decisions. We investigate whether frontier language models can accurately classify transcripts based on whether they originate from evaluations or real-world deployment, a capability we call evaluation awareness. To achieve this, we construct a diverse benchmark of 1,000 prompts and transcripts from 61 distinct datasets. These span public benchmarks (e.g., MMLU, SWEBench), real-world deployment interactions, and agent trajectories from scaffolding frameworks (e.g., web-browsing agents). Frontier models clearly demonstrate above-random evaluation awareness (Gemini-2.5-Pro reaches an AUC of $0.83$), but do not yet surpass our simple human baseline (AUC of $0.92$). Furthermore, both AI models and humans are better at identifying evaluations in agentic settings compared to chat settings. Additionally, we test whether models can identify the purpose of the evaluation. Under multiple-choice and open-ended questioning, AI models far outperform random chance in identifying what an evaluation is testing for. Our results indicate that frontier models already exhibit a substantial, though not yet superhuman, level of evaluation-awareness. We recommend tracking this capability in future models.
Forecasting Frontier Language Model Agent Capabilities
Feb 21, 2025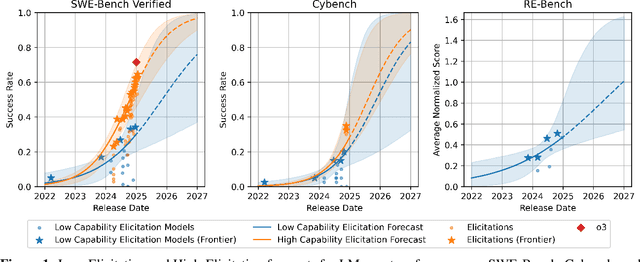

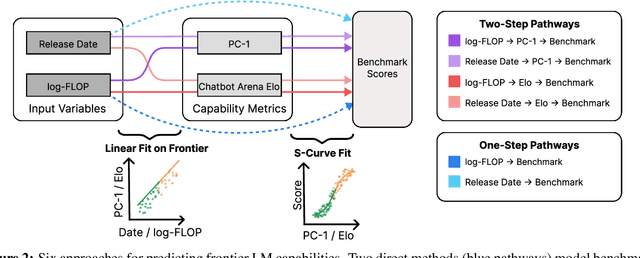
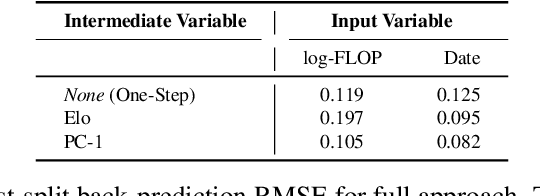
As Language Models (LMs) increasingly operate as autonomous agents, accurately forecasting their capabilities becomes crucial for societal preparedness. We evaluate six forecasting methods that predict downstream capabilities of LM agents. We use "one-step" approaches that predict benchmark scores from input metrics like compute or model release date directly or "two-step" approaches that first predict an intermediate metric like the principal component of cross-benchmark performance (PC-1) and human-evaluated competitive Elo ratings. We evaluate our forecasting methods by backtesting them on a dataset of 38 LMs from the OpenLLM 2 leaderboard. We then use the validated two-step approach (Release Date$\to$Elo$\to$Benchmark) to predict LM agent performance for frontier models on three benchmarks: SWE-Bench Verified (software development), Cybench (cybersecurity assessment), and RE-Bench (ML research engineering). Our forecast predicts that by the beginning of 2026, non-specialized LM agents with low capability elicitation will reach a success rate of 54% on SWE-Bench Verified, while state-of-the-art LM agents will reach an 87% success rate. Our approach does not account for recent advances in inference-compute scaling and might thus be too conservative.
Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Oct 08, 2024



Recently, language models like Llama 3.1 Instruct have become increasingly capable of agentic behavior, enabling them to perform tasks requiring short-term planning and tool use. In this study, we apply refusal-vector ablation to Llama 3.1 70B and implement a simple agent scaffolding to create an unrestricted agent. Our findings imply that these refusal-vector ablated models can successfully complete harmful tasks, such as bribing officials or crafting phishing attacks, revealing significant vulnerabilities in current safety mechanisms. To further explore this, we introduce a small Safe Agent Benchmark, designed to test both harmful and benign tasks in agentic scenarios. Our results imply that safety fine-tuning in chat models does not generalize well to agentic behavior, as we find that Llama 3.1 Instruct models are willing to perform most harmful tasks without modifications. At the same time, these models will refuse to give advice on how to perform the same tasks when asked for a chat completion. This highlights the growing risk of misuse as models become more capable, underscoring the need for improved safety frameworks for language model agents.
Analyzing Probabilistic Methods for Evaluating Agent Capabilities
Sep 24, 2024

To mitigate risks from AI systems, we need to assess their capabilities accurately. This is especially difficult in cases where capabilities are only rarely displayed. Phuong et al. propose two methods that aim to obtain better estimates of the probability of an AI agent successfully completing a given task. The milestone method decomposes tasks into subtasks, aiming to improve overall success rate estimation, while the expert best-of-N method leverages human guidance as a proxy for the model's independent performance. Our analysis of these methods as Monte Carlo estimators reveals that while both effectively reduce variance compared to naive Monte Carlo sampling, they also introduce bias. Experimental results demonstrate that the milestone method underestimates true solve rates for many real-world tasks due to its constraining assumptions. The expert best-of-N method exhibits even more severe underestimation across all tasks, attributed to an inherently flawed re-weighting factor. To enhance the accuracy of capability estimates of AI agents on difficult tasks, we suggest future work should leverage the rich literature on Monte Carlo Estimators.