 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress Testing Deliberative Alignment for Anti-Scheming Training
Sep 19, 2025



Highly capable AI systems could secretly pursue misaligned goals -- what we call "scheming". Because a scheming AI would deliberately try to hide its misaligned goals and actions, measuring and mitigating scheming requires different strategies than are typically used in ML. We propose that assessing anti-scheming interventions requires at least (1) testing propensity to scheme on far out-of-distribution (OOD) tasks, (2) evaluating whether lack of scheming is driven by situational awareness, and (3) checking for robustness to pre-existing misaligned goals. We use a broad category of "covert actions" -- such as secretly breaking rules or intentionally underperforming in tests -- as a proxy for scheming, and design evaluations for covert actions. We then stress-test deliberative alignment as a case study for anti-scheming. Across 26 OOD evaluations (180+ environments), deliberative alignment reduces covert action rates (OpenAI o3: 13%->0.4%) but does not fully eliminate them. Our mitigation is also able to largely stop agents from pursuing a hidden goal previously trained into the model, but we still find misbehavior after additional red-teaming. We find that models' chain-of-thought (CoT) often demonstrates awareness of being evaluated for alignment, and show causal evidence that this awareness decreases covert behavior, while unawareness increases it. Therefore, we cannot exclude that the observed reductions in covert action rates are at least partially driven by situational awareness. While we rely on human-legible CoT for training, studying situational awareness, and demonstrating clear evidence of misalignment, our ability to rely on this degrades as models continue to depart from reasoning in standard English. We encourage research into alignment mitigations for scheming and their assessment, especially for the adversarial case of deceptive alignment, which this paper does not address.
Forecasting Frontier Language Model Agent Capabilities
Feb 21, 2025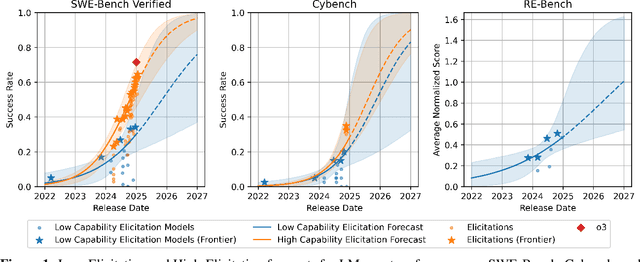

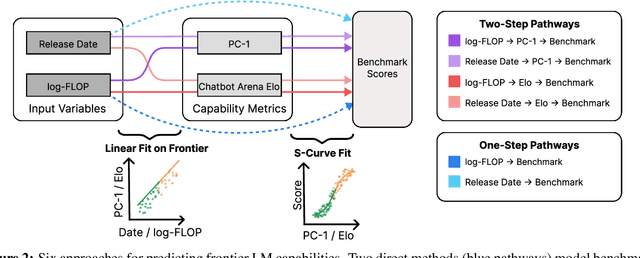
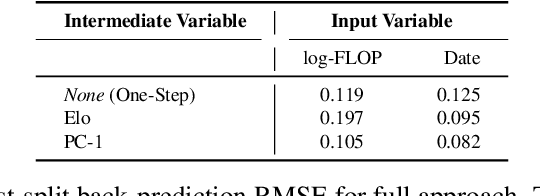
As Language Models (LMs) increasingly operate as autonomous agents, accurately forecasting their capabilities becomes crucial for societal preparedness. We evaluate six forecasting methods that predict downstream capabilities of LM agents. We use "one-step" approaches that predict benchmark scores from input metrics like compute or model release date directly or "two-step" approaches that first predict an intermediate metric like the principal component of cross-benchmark performance (PC-1) and human-evaluated competitive Elo ratings. We evaluate our forecasting methods by backtesting them on a dataset of 38 LMs from the OpenLLM 2 leaderboard. We then use the validated two-step approach (Release Date$\to$Elo$\to$Benchmark) to predict LM agent performance for frontier models on three benchmarks: SWE-Bench Verified (software development), Cybench (cybersecurity assessment), and RE-Bench (ML research engineering). Our forecast predicts that by the beginning of 2026, non-specialized LM agents with low capability elicitation will reach a success rate of 54% on SWE-Bench Verified, while state-of-the-art LM agents will reach an 87% success rate. Our approach does not account for recent advances in inference-compute scaling and might thus be too conservative.
Analyzing Probabilistic Methods for Evaluating Agent Capabilities
Sep 24, 2024

To mitigate risks from AI systems, we need to assess their capabilities accurately. This is especially difficult in cases where capabilities are only rarely displayed. Phuong et al. propose two methods that aim to obtain better estimates of the probability of an AI agent successfully completing a given task. The milestone method decomposes tasks into subtasks, aiming to improve overall success rate estimation, while the expert best-of-N method leverages human guidance as a proxy for the model's independent performance. Our analysis of these methods as Monte Carlo estimators reveals that while both effectively reduce variance compared to naive Monte Carlo sampling, they also introduce bias. Experimental results demonstrate that the milestone method underestimates true solve rates for many real-world tasks due to its constraining assumptions. The expert best-of-N method exhibits even more severe underestimation across all tasks, attributed to an inherently flawed re-weighting factor. To enhance the accuracy of capability estimates of AI agents on difficult tasks, we suggest future work should leverage the rich literature on Monte Carlo Estimators.