 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Frontier Language Model Agent Capabilities
Paper and Code
Feb 21, 2025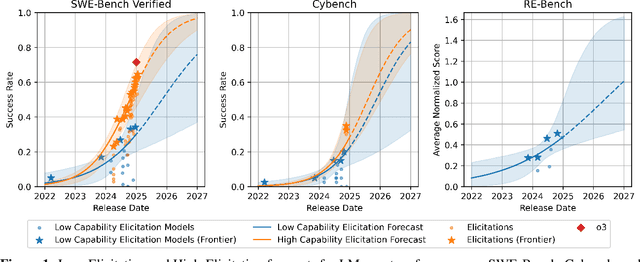

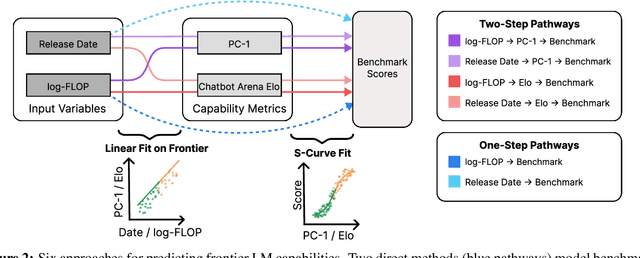
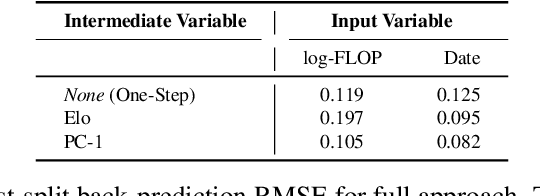
As Language Models (LMs) increasingly operate as autonomous agents, accurately forecasting their capabilities becomes crucial for societal preparedness. We evaluate six forecasting methods that predict downstream capabilities of LM agents. We use "one-step" approaches that predict benchmark scores from input metrics like compute or model release date directly or "two-step" approaches that first predict an intermediate metric like the principal component of cross-benchmark performance (PC-1) and human-evaluated competitive Elo ratings. We evaluate our forecasting methods by backtesting them on a dataset of 38 LMs from the OpenLLM 2 leaderboard. We then use the validated two-step approach (Release Date$\to$Elo$\to$Benchmark) to predict LM agent performance for frontier models on three benchmarks: SWE-Bench Verified (software development), Cybench (cybersecurity assessment), and RE-Bench (ML research engineering). Our forecast predicts that by the beginning of 2026, non-specialized LM agents with low capability elicitation will reach a success rate of 54% on SWE-Bench Verified, while state-of-the-art LM agents will reach an 87% success rate. Our approach does not account for recent advances in inference-compute scaling and might thus be too conservative.