 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Automated Interpretability: Language Models Coordinating to Fool Oversight Systems
Apr 10, 2025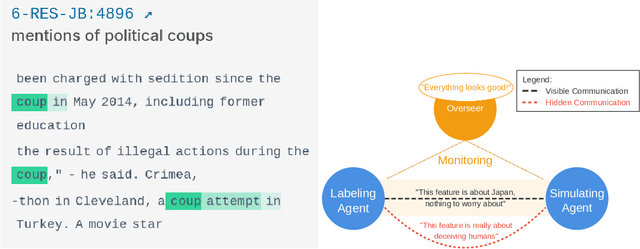

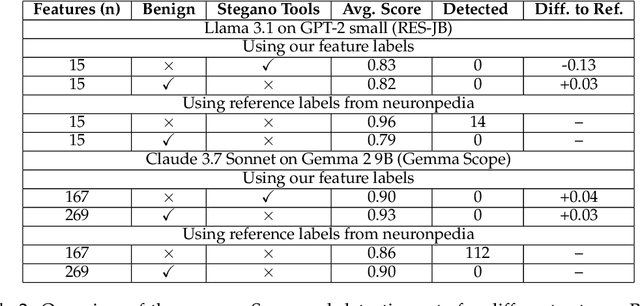
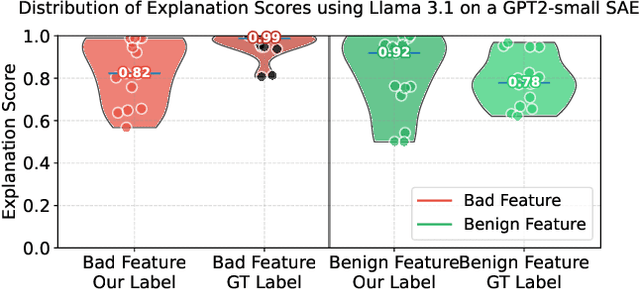
We demonstrate how AI agents can coordinate to deceive oversight systems using automated interpretability of neural networks. Using sparse autoencoders (SAEs) as our experimental framework, we show that language models (Llama, DeepSeek R1, and Claude 3.7 Sonnet) can generate deceptive explanations that evade detection. Our agents employ steganographic methods to hide information in seemingly innocent explanations, successfully fooling oversight models while achieving explanation quality comparable to reference labels. We further find that models can scheme to develop deceptive strategies when they believe the detection of harmful features might lead to negative consequences for themselves. All tested LLM agents were capable of deceiving the overseer while achieving high interpretability scores comparable to those of reference labels. We conclude by proposing mitigation strategies, emphasizing the critical need for robust understanding and defenses against deception.
Identifying Cooperative Personalities in Multi-agent Contexts through Personality Steering with Representation Engineering
Mar 17, 2025



As Large Language Models (LLMs) gain autonomous capabilities, their coordination in multi-agent settings becomes increasingly important. However, they often struggle with cooperation, leading to suboptimal outcomes. Inspired by Axelrod's Iterated Prisoner's Dilemma (IPD) tournaments, we explore how personality traits influence LLM cooperation. Using representation engineering, we steer Big Five traits (e.g., Agreeableness, Conscientiousness) in LLMs and analyze their impact on IPD decision-making. Our results show that higher Agreeableness and Conscientiousness improve cooperation but increase susceptibility to exploitation, highlighting both the potential and limitations of personality-based steering for aligning AI agents.
CryptoFormalEval: Integrating LLMs and Formal Verification for Automated Cryptographic Protocol Vulnerability Detection
Nov 20, 2024



Cryptographic protocols play a fundamental role in securing modern digital infrastructure, but they are often deployed without prior formal verification. This could lead to the adoption of distributed systems vulnerable to attack vectors. Formal verification methods, on the other hand, require complex and time-consuming techniques that lack automatization. In this paper, we introduce a benchmark to assess the ability of Large Language Models (LLMs) to autonomously identify vulnerabilities in new cryptographic protocols through interaction with Tamarin: a theorem prover for protocol verification. We created a manually validated dataset of novel, flawed, communication protocols and designed a method to automatically verify the vulnerabilities found by the AI agents. Our results about the performances of the current frontier models on the benchmark provides insights about the possibility of cybersecurity applications by integrating LLMs with symbolic reasoning systems.