 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Automated Interpretability: Language Models Coordinating to Fool Oversight Systems
Paper and Code
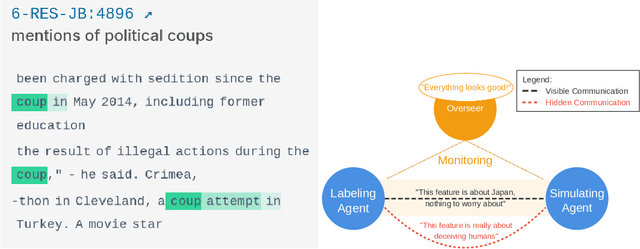

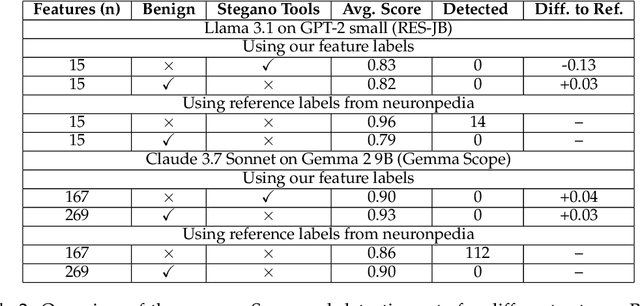
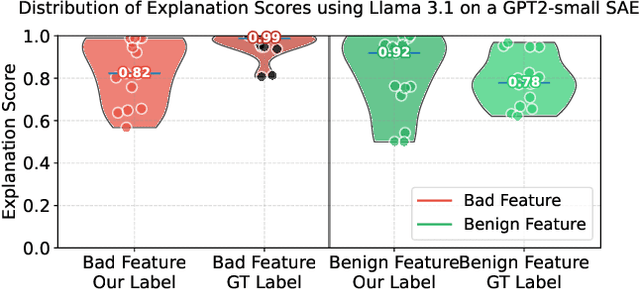
We demonstrate how AI agents can coordinate to deceive oversight systems using automated interpretability of neural networks. Using sparse autoencoders (SAEs) as our experimental framework, we show that language models (Llama, DeepSeek R1, and Claude 3.7 Sonnet) can generate deceptive explanations that evade detection. Our agents employ steganographic methods to hide information in seemingly innocent explanations, successfully fooling oversight models while achieving explanation quality comparable to reference labels. We further find that models can scheme to develop deceptive strategies when they believe the detection of harmful features might lead to negative consequences for themselves. All tested LLM agents were capable of deceiving the overseer while achieving high interpretability scores comparable to those of reference labels. We conclude by proposing mitigation strategies, emphasizing the critical need for robust understanding and defenses against deception.