 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning with Heterogeneous Preferences for Kidney Exchange
Paper and Code


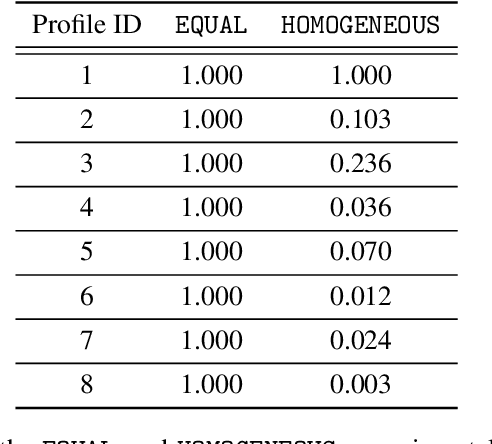
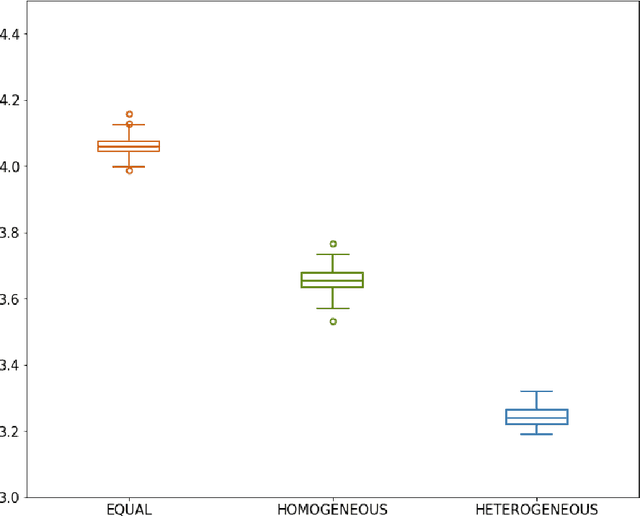
AI algorithms increasingly make decisions that impact entire groups of humans. Since humans tend to hold varying and even conflicting preferences, AI algorithms responsible for making decisions on behalf of such groups encounter the problem of preference aggregation: combining inconsistent and sometimes contradictory individual preferences into a representative aggregate. In this paper, we address this problem in a real-world public health context: kidney exchange. The algorithms that allocate kidneys from living donors to patients needing transplants in kidney exchange matching markets should prioritize patients in a way that aligns with the values of the community they serve, but allocation preferences vary widely across individuals. In this paper, we propose, implement and evaluate a methodology for prioritizing patients based on such heterogeneous moral preferences. Instead of selecting a single static set of patient weights, we learn a distribution over preference functions based on human subject responses to allocation dilemmas, then sample from this distribution to dynamically determine patient weights during matching. We find that this methodology increases the average rank of matched patients in the sampled preference ordering, indicating better satisfaction of group preferences. We hope that this work will suggest a roadmap for future automated moral decision making on behalf of heterogeneous groups.